
MPI-Povray Performance Report
After running all of these povray cases under the path : /home/rider/scenes (default:/opt/povray31/scenes) , i have choose 5 (*.pov)files which are the highest cpu consumption(最耗運算資源-光影相關運算)for mpi-povray to run performance test.
All of the rendered files had been put in the /home/rider/povray_demo directory.
Rendered files for the performance experiment are listed below...
/home/rider/scenes/advanced/woodbox.pov
/home/rider/objects/pawns.pov
/home/rider/scenes/advanced/whiltile.pov
/home/rider/scenes/interior/ballbox.pov
/home/rider/scenes/advanced/quilt1.pov
Experiment Case
We have 4 experiment cases:
case1: 1024 x 768
case2: 2048 x 1536
case3: 4096 x 3072
case4: 8192 x 6144
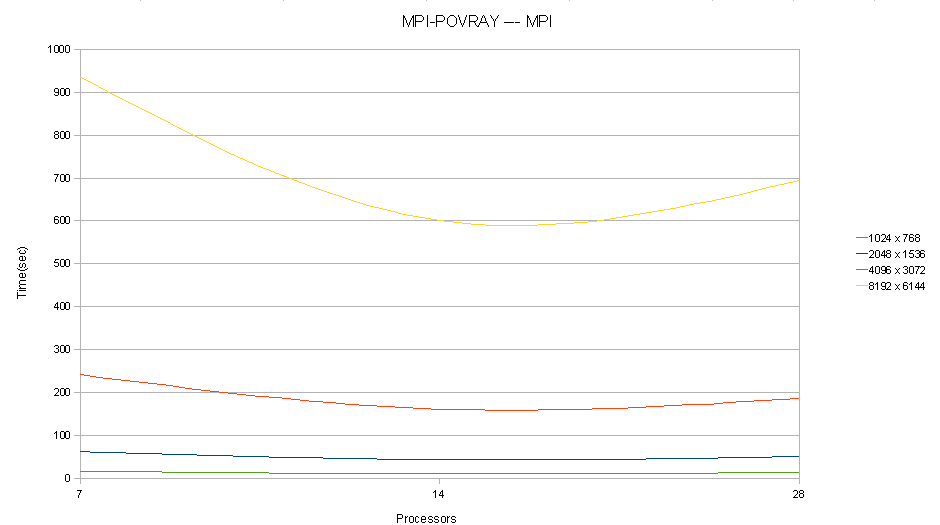
MPI-POVRAY - MPI Only
Machinefile:
#MPI Machinefile
node1:4
node2:4
node3:4
node4:4
node5:4
node6:4
node7:4
# End of Machinefile
case1.1: Resolution 1024 x 768: Running 5 *.pov continuously with np7 takes 16 secs to finish rendering
case2.1: Resolution 2048 x 1536: Running 5 *.pov continuously with np7 takes 62 secs to finish rendering
case3.1: Resolution 4096 x 3072: Running 5 *.pov continuously with np7 takes 241 secs to finish rendering
case4.1: Resolution 8192 x 6144: Running 5 *.pov continuously with np7 takes 935 secs to finish rendering
case1.2: Resolution 1024 x 768: Running 5 *.pov continuously with np14 takes 10 secs to finish rendering
case2.2: Resolution 2048 x 1536: Running 5 *.pov continuously with np14 takes 43 secs to finish rendering
case3.2: Resolution 4096 x 3072: Running 5 *.pov continuously with np14 takes 161 secs to finish rendering
case4.2: Resolution 8192 x 6144: Running 5 *.pov continuously with np14 takes 601 secs to finish rendering
case1.3: Resolution 1024 x 768: Running 5 *.pov continuously with np28 takes 13 secs to finish rendering
case2.3: Resolution 2048 x 1536: Running 5 *.pov continuously with np28 takes 50 secs to finish rendering
case3.3: Resolution 4096 x 3072: Running 5 *.pov continuously with np28 takes 185 secs to finish rendering
case4.3: Resolution 8192 x 6144: Running 5 *.pov continuously with np28 takes 695 secs to finish rendering
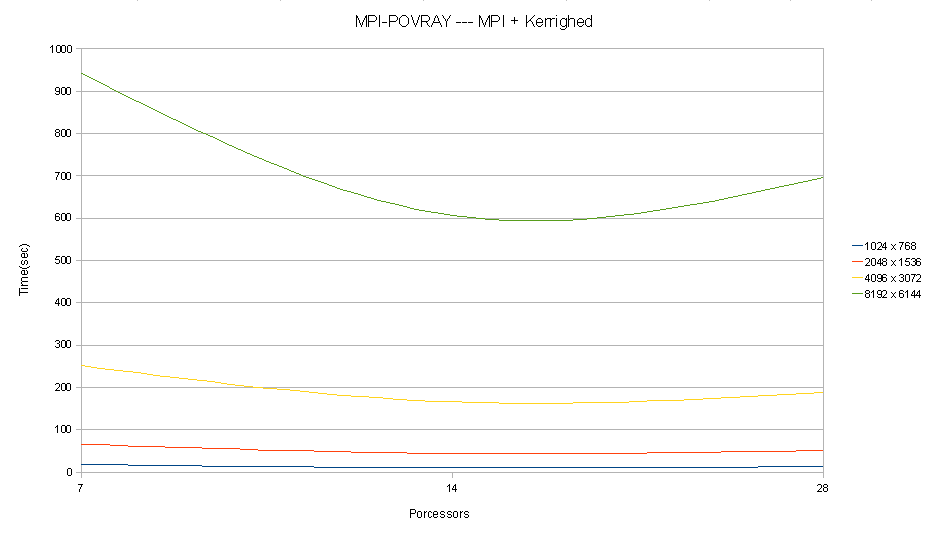
MPI-POVRAY - MPI + Kerrighed
#MPI+Kerrighed Machinefile
node1:4
node1:4
node1:4
node1:4
node1:4
node1:4
node1:4
# End of Machinefile
case1.1: Resolution 1024 x 768: Running 5 *.pov continuously with np7 takes 18 secs to finish rendering
case2.1: Resolution 2048 x 1536: Running 5 *.pov continuously with np7 takes 66 secs to finish rendering
case3.1: Resolution 4096 x 3072: Running 5 *.pov continuously with np7 takes 251 secs to finish rendering
case4.1: Resolution 8192 x 6144: Running 5 *.pov continuously with np7 takes 942 secs to finish rendering
case1.2: Resolution 1024 x 768: Running 5 *.pov continuously with np14 takes 10 secs to finish rendering
case2.2: Resolution 2048 x 1536: Running 5 *.pov continuously with np14 takes 44 secs to finish rendering
case3.2: Resolution 4096 x 3072: Running 5 *.pov continuously with np14 takes 166 secs to finish rendering
case4.2: Resolution 8192 x 6144: Running 5 *.pov continuously with np14 takes 606 secs to finish rendering
case1.3: Resolution 1024 x 768: Running 5 *.pov continuously with np28 takes 13 secs to finish rendering
case2.3: Resolution 2048 x 1536: Running 5 *.pov continuously with np28 takes 51 secs to finish rendering
case3.3: Resolution 4096 x 3072: Running 5 *.pov continuously with np28 takes 187 secs to finish rendering
case4.3: Resolution 8192 x 6144: Running 5 *.pov continuously with np28 takes 696 secs to finish rendering
Or
#MPI+Kerrighed Machinefile
node1:28
# End of Machinefile
Problem1: Using this machinefile,we only get one node running povary process by 4 CPUs and the others are almost nothing to do.
Solution1:
Step1: rider@node101:~$ krg_capset -e +CAN_MIGRATE
Step2: rider@node101:~$ migrate pid nodeid
Solution2:
When running an MPI application on Kerrighed, be sure to :
1 - You have only "localhost" in your node list file
2 - You do not create local process with mpirun ("-nolocal" option with MPICH)
3 - You have compiled MPICH with RSH_COMMAND = "'krg_rsh"
4 - Be sure the Kerrighed scheduler is loaded (modules cpu_scheduler2, etc)
5 - Be sure to enable process distant fork and use of kerrighed dynamic streams (in the terminal you launch MPI applications in, use the shell command krg_capset -d +DISTANT_FORK,USE_INTRA_CLUSTER_KERSTREAMS)
rider@node101:~$ krgcapset -d +DISTANT_FORK,USE_INTRA_CLUSTER_KERSTREAMS,CAN_MIGRATE
Reference URL:
http://131.254.254.17/mpi.php
http://kerrighed.org/forum/viewtopic.php?t=42
http://www.metz.supelec.fr/metz/recherche/ersidp/Publication/OnLineFiles/05-Ifrim-2004-05.pdf
Problem2: Running-povray process cannot fork very well for kerrighed to migrate.
Conclusion:
Is kerrighed getting more powerful than parallel computing by comparing with the attached files ? We find that even if you get more processors or nodes adding to your task, but it does't guarantee the performance as you wish. It seems to have an optimized nodes numbers (CPUs) to get to the extra performance, so it can be well-suited for making different kinds of experiments case by case.
MPI uses (by default) sockets in order to allow the communication between processes on different machines, Kerrighed installed system must be instructed with the available Kerrighed capabilities to link the created sockets to Kernet streams and to use a special rsh program for process deployment - krg-rsh. The MPI library and the runtime will be used unchanged. With the configurations mentioned above, Kerrighed scheduler will menage the deployment of the MPI program.
MPI processes are deployed and managed by the current scheduler: they therefore theoretically can be migrated to balance the load on all nodes, and be deployed in an unexpected way if other programs are running on the cluster.The first test that we made with MPI on Kerrighed had the role to see if Kerrighed and MPI can run independently and if Kerrighed introduces some great overhead in the MPI communication. The application did only a lot of broadcasts and message sending between processes.
We may have more other tests to try in order to see if we can take benefit of the combination of MPI and IPC on the Kerrighed cluster upon to our usage scenario.
### Performance note: For the attached file: mpi-povray performance_result.odt
Attachments (4)
-
mpi-povray.sh
(400 bytes) -
added by rider 18 years ago.
mpi-povray performance script
-
mpi-povray performance_result.odt
(32.7 KB) -
added by rider 18 years ago.
MPI POV-Ray Performance Result
-
MPI-POVRAY --- MPI.PNG
(13.5 KB) -
added by rider 18 years ago.
MPI-POVRAY --- MPI
-
MPI-POVRAY --- MPI + Kerrighed.PNG
(14.5 KB) -
added by rider 18 years ago.
MPI-POVRAY --- MPI + Kerrighed
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip