
| Version 15 (modified by jazz, 16 years ago) (diff) |
|---|
2010-03-31
IDEA: Cloud CPU
- 今天中午在跟擅長 GPU 與平行運算的郭芳安同仁聊天,除了談到怎麼讓 Multiple GPU 可以透過 pthread, OpenMP, MPI 作協同運作外,也談到目前的應用瓶頸主要還是在 Data I/O Throughput,這裡講的並不是最前面讀取資料,最後面寫回硬碟(SAN, NAS, 或 D/P File System)的資料通量,而是在運算過程中的資料通量,可能發生在網路卡之間(MPI job),可能發生在 CPU 經過北橋晶片,存取記憶體的過程。目前最大的問題還是在於 CPU 無法直接存取記憶體,因此 CPU 根本「吃不飽」。在現階段我們的一些省電測試中,確實光是四核心 CPU 就很難餵飽它,讓它一直維持 100%。目前最接近的 CPU 架構應該是 Blue Gene,當然我也提到過去在觀察的 Network Processor。不過最後我們得到一個結論,就是如果有一種 CPU 架構可以直接存取網路跟記憶體,那這種 CPU 大概是最適合高效能運算(HPC)的吧。

Green Computing : Energy Efficiency : DRBL/Clonezilla over NAS
- 關於 Network Processor 目前大多數應用在 NAS 裝置上,因此今天跟哲源討論的時候,談到或許把 NFS 甚至整個 DRBL Server 移植到 NAS 上,搞不好會最省電,因為 CPU 特性的原因。但是這樣造成另一個問題,由於通常 NAS 是 ARM 或 MIPS 等架構,縱使可以裝 Debian,但卻不能拿來接 x86 架構的個人電腦作備份還原。因為光是 linux kernel, glibc 就造成很大的差異。這個問題跟 32 位元的 server 配上 64 位元的 client 有異曲同工之妙,會遇到不同 CPU 架構造成的異質性問題。
Configuration Management Tool
- 先前常遇到 DRBL 在整合一些叢集軟體的設定檔案問題,有時 Server 跟 Client 必須不同,這就有點跟原始 DRBL 用意不太一致,也容易因為重跑 DRBL redeploy 而需要重新修改,特別是 /etc/hosts。是否該整合所謂 Configuration Management 的軟體,來協助部署像是 Hadoop 或者 Lustre 這種軟體呢?値得評估看看,但第一步可能還是得先了解一下這些 Configuration Management Tool 的用法。
- 參考 Hadoop Wiki 有提到幾種:bcfg2, SmartFrog, Puppet, cfengine
Consider a system configuration management package to keep Hadoop's source and configuration consistent across all nodes. Some example packages are bcfg2, SmartFrog, Puppet, cfengine, etc.
- Deploying Apache Hadoop with SmartFrog
- http://smartfrog.org/ - 由 HP 實驗室設計的叢集設定軟體(Configuration Management tools, CM-tool)
- Bcfg2 是由 Argonne National Laboratory 開發的 - Debian 有 bcfg2 套件
- Cfengine (configuration engine) - 自動化管理工具,甚至號稱未來可以管理雲端 - Newly Released Cfengine 3 will Manage Resource Clouds
- puppet 是一套用來佈署叢集設定檔的工具。不過....從東京大學IRT研究機構(Information and Robot Technology Research Initiative)的叢集管理實務經驗顯示:還挺吃記憶體的 - Debian 有 puppet 套件
- 在另一個 mail list (Best CFM Engine for Hadoop) 中看到有人建議 Spacewalk(太空漫步), 連 Logo 都是太空漫步呢 :)
- 根據 google trends 排行榜,cfengine 還是大獲全勝,至於 puppet 因為跟木偶同意,所以不準。初步選擇 cfengine, puppet 來看一下,至於需要資料庫的 SmartFrog 則排在第三順位。

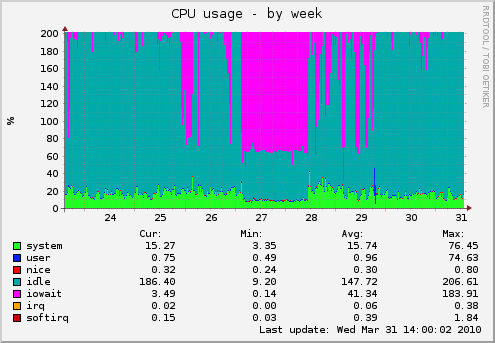
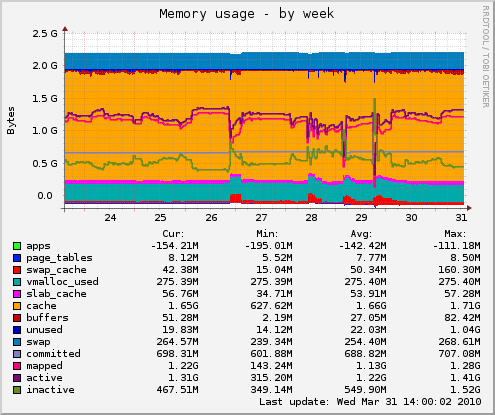
I/O Intensive Virtualization
- 最近 trac 一直不太順,本以為是有大量網路攻擊造成,但也觀察到另一個現象,就是虛擬機器的 host OS 若出現 IOWait 就會影響虛擬機器效能。跟 thomas 討論過,已知若採用 FLAT 格式的 VMDK 比較不會有這種問題,但是如果是支援 Copy-On-Write (COW) 動態成長的虛擬硬碟就容易有效能上的 overhead。因此這裡出現了一個新的問題,虛擬化平台上是否合適執行 I/O Intensive 的虛擬機器呢?? 還是最好讓虛擬機器直接掛載實體硬碟會比較妥當呢?? 先前也有聽過 Database 虛擬化之後,整體效能嚴重降低的問題,而 Hadoop 若放在 Xen 上跑,Cloudera 的 Christophe 似乎也不是非常建議。
- [解決方法] 初步想到的解決方法:
- VM 採用 local Disk Partition
- VM 採用 iSCSI Disk or use Distributed/Parallel? File System to share heavy I/O (分散 I/O 到多顆 Disk)
- 當然最消極作為是 Data Intensive Job 最好還是在實體機器上跑。
- [注意事項]
- 當然不管是當 Data Intensive 計算主機還是 VM Host 主機,都最好不要吃到 SWAP,否則只有一個字:「慘」!!!
- 這也就代表....記憶體總容量比 CPU 多核重要 (跟上面講的還是一致,多核餵不飽,而且如果記憶體不夠大,更不可能餵飽它)
- 先前 Hadoop 叢集常掛也是因為吃到 SWAP,現在 VM Host 雖然沒有掛,但卻造成 VM Client 嚴重的延遲。
- [研究議題]
- 謎之聲:那最好的 "RAM GB / CPU Core 個數" 這個數值會是多少呢 ???
- Virtual I/O : I/O 如何虛擬化?? 先前看過 PCI Express 有支援 IOMMU ...
- 系統監控、資源排程(Resource Scheduling and Provisioning)、動態負載平衡(Dynamic Load Balance)需要考慮平均 I/O 上限是否超出單台負載。


- 那麼 IOWait 有什麼好的解決知道呢?? - [參考文章] IOWait 相關問題(簡)
IOWait 高的一些處理方法 1、如果有使用 RAID,請檢查 RAID 的狀態,例如:是否正在重建或者沒有初始化 2、更換作業系統的核心,最好使用發行版標準的 Linux kernel,因為有比較多的修補 3、檢查 /proc/sys/vm 下面是否可以最佳化 4、是否使用了檔案系統,檔案系統是否有最佳化的選項,比如在 RAID5 上採用 xfs 文件系統時, 可以調節一些參數優化性能 5、客戶端程式是否產生了過大的壓力,比如磁碟的讀寫效能只有 10MB/s,每個執行緒的讀寫 速度為 5 MB/s,那麼如果讀寫執行緒個數為 20 的話,無疑會造成 IOWait 過高 6、查看進程狀態 ps -eo pid,user,wchan=WIDE-WCHAN-COLUMN -o s,cmd|awk ' $4 ~ /D/ {print $0}' lsof -p $pid 7、使用block_dump /etc/init.d/syslog stop echo 1 > /proc/sys/vm/block_dump sleep 60 dmesg | awk '/(READ|WRITE|dirtied)/ {process[$1]++} END {for (x in process) \ print process[x],x}' |sort -nr |awk '{print $2 " " $1}' | \ head -n 10 echo 0 > /proc/sys/vm/block_dump /etc/init.d/syslog start - [參考] LISA'09 的 Tutorial 列了不少 performance tuning
* Performance tuning strategies o Practical goals o Monitoring intervals o Useful statistics o Tools, tools, tools * Server tuning o Filesystem and disk tuning o Memory consumption and swap space o System resource monitoring * NFS performance tuning o NFS server constraints o NFS client improvements o NFS over WANs o Automounter and other tricks * Network performance, design, and capacity planning o Locating bottlenecks o Demand management o Media choices and protocols o Network topologies: bridges, switches, and routers o Throughput and latency considerations o Modeling resource usage * Application tuning o System resource usage o Memory allocation o Code profiling o Job scheduling and queuing o Real-time issues o Managing response time ---------------- # High-performance I/O * Advanced file systems and the LVM * Disk striping * Optimizing I/O performance # Advanced compute-server environments * HPC with Beowulf * Clustering and high availability * Parallelization environments/facilities * CPU performance optimization # Enterprise-wide security features, including centralized authentication # Automation techniques and facilities # Linux performance tuning ---------------- # NFS performance tuning * NFS server constraints * NFS client improvements * NFS over WANs * Automounter and other tricks # Application tuning * System resource usage * Memory allocation * Code profiling * Job scheduling and queuing * Real-time issues * Managing response time ----------------
Mobile Computing
- 今天看到洪朝貴老師的 e 管家文章,雖然先前知道這東西,但沒啥動力要裝。倒是對老師文章中提到的手機作業系統排行榜有興趣。
- 根據 Garnter 的研究,到 2012 年,Symbian 跟 Android 會排手機作業系統的前兩名,第三名是 iPhone。1
- 2009-05-29 : Comparing Smartphone Market Share by Operating System - 這篇文章的圖蠻有意思的,說明了用 iPhone 看 HTML 網站的比例非常高,或許跟螢幕夠大有關吧 :)
- Garnter 2009 年的研究,比例上手機作業系統排行是 Symbian (52%) > RIM (17%) > Windows (12%) > iPhone (8%) > > Plam (2%) = Other(2%) > Android (1%)

Attachments (3)
- 10-03-31_cfengine_trends.png (19.6 KB) - added by jazz 16 years ago.
- 10-03-31_vmhost-cpu-week.png (27.2 KB) - added by jazz 16 years ago.
- 10-03-31_vmhost-memory-week.png (38.2 KB) - added by jazz 16 years ago.
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip