
Change Log
- <update> 20111019 解決 中文分詞 問題。輸入: 解析度 會出現錯誤
- <update> 20110901 IKAnalyzer3.2.8_waue.jar 重編
編譯
下載解壓縮 nutch-1.2 (目前用 nutch-1.2-bin.tar.gz)
cd $nutch-1.2/ vim src/java/org/apache/nutch/analysis/NutchAnalysis.jj
| <SIGRAM: (<CJK>)+ >
- 用編譯器 javacc 編譯出七個java檔
CharStream.java NutchAnalysisTokenManager.java TokenMgrError.java NutchAnalysisConstants.java ParseException.java NutchAnalysis.java Token.java
cd $nutch-1.2/src/java/org/apache/nutch/analysis javacc -OUTPUT_DIRECTORY=./ika/ NutchAnalysis.jj mv ./ika/* ./ ; rmdir ika;
- 編譯剛編出來的 NutchAnalysis.java
vim $nutch-1.2/src/java/org/apache/nutch/analysis/NutchAnalysis.java
- 加入ParseException (共兩處):
public static Query parseQuery(....) throws IOException,ParseException
/opt/nutch-1.2/src/java/org/apache/nutch/searcher/Query.java
(:456) public static Query parse(String queryString, String queryLang, Configuration conf) throws IOException { Query que; try { que = fixup(NutchAnalysis.parseQuery( queryString, AnalyzerFactory.get(conf).get(queryLang), conf), conf); }catch (org.apache.nutch.analysis.ParseException e){ que = new Query(); } return que; }
- 下載 IKAnalyzer3.2.8.jar (2011/07/29) 解壓縮
- 此處可以使用官方原始檔來編譯 ,但最後要讓 nutch 頁面索引時索引入的IKAnalyzer 需要修正過,可直接使用我修好的 IKAnalyzer3.2.8_waue.jar
http://code.google.com/p/ik-analyzer/downloads/list
nutch-1.2 用的是 lucene-core-3.0.1.jar , 因此對應 ikanalyzer 為 3.2.8 版本
3.1.6GA 兼容 2.9.1 及先前版本 对 solr1.3、solr1.4 提供接口实现 3.2.0G 及后续版本 兼容 Lucene2.9 及 3.0 版本 仅对 solr1.4 提供接口实现
丌支持 Lucene2.4 及先前版本
IKAnalyzer3.2.8 bin.zip 內的 IKAnalyzer3.2.8.jar 解壓縮出來,分別放到以下資料夾
cp IKAnalyzer3.2.8.jar $nutch-1.2/lib/ cp IKAnalyzer3.2.8.jar $my_nutch_dir/lib/ cp IKAnalyzer3.2.8.jar $my_tomcat_dir/webapps/ROOT/WEB-INF/lib
- 修改 NutchDocumentAnalyzer?.java 程式碼
vim src/java/org/apache/nutch/analysis/NutchDocumentAnalyzer.java
將
public TokenStream tokenStream(String fieldName, Reader reader) {
Analyzer analyzer;
if ("anchor".equals(fieldName))
analyzer = ANCHOR_ANALYZER;
else
analyzer = CONTENT_ANALYZER;
return analyzer.tokenStream(fieldName, reader);
}
改成
public TokenStream tokenStream(String fieldName, Reader reader) {
Analyzer analyzer;
if ("anchor".equals(fieldName))
analyzer = ANCHOR_ANALYZER;
else
//analyzer = CONTENT_ANALYZER;
analyzer = new org.wltea.analyzer.lucene.IKAnalyzer();
return analyzer.tokenStream(fieldName, reader);
}
- 修改 build.xml
<include name="IKAnalyzer*.jar"/>
- 修改中文分詞錯誤
問題描述:
由於Nutch不是原生支持中文的,開發者沒有考慮到中文的分詞會存在token的交叉重疊的情況,導致在根據用戶輸入查詢串的token獲取頁面summary時出現:StringIndexOutOfBoundsException的異常。比如:「教育方針」可能出現這樣的分詞「教育方針」、「教育」、「方針」,這幾個token就交叉重疊了。
錯誤重現:
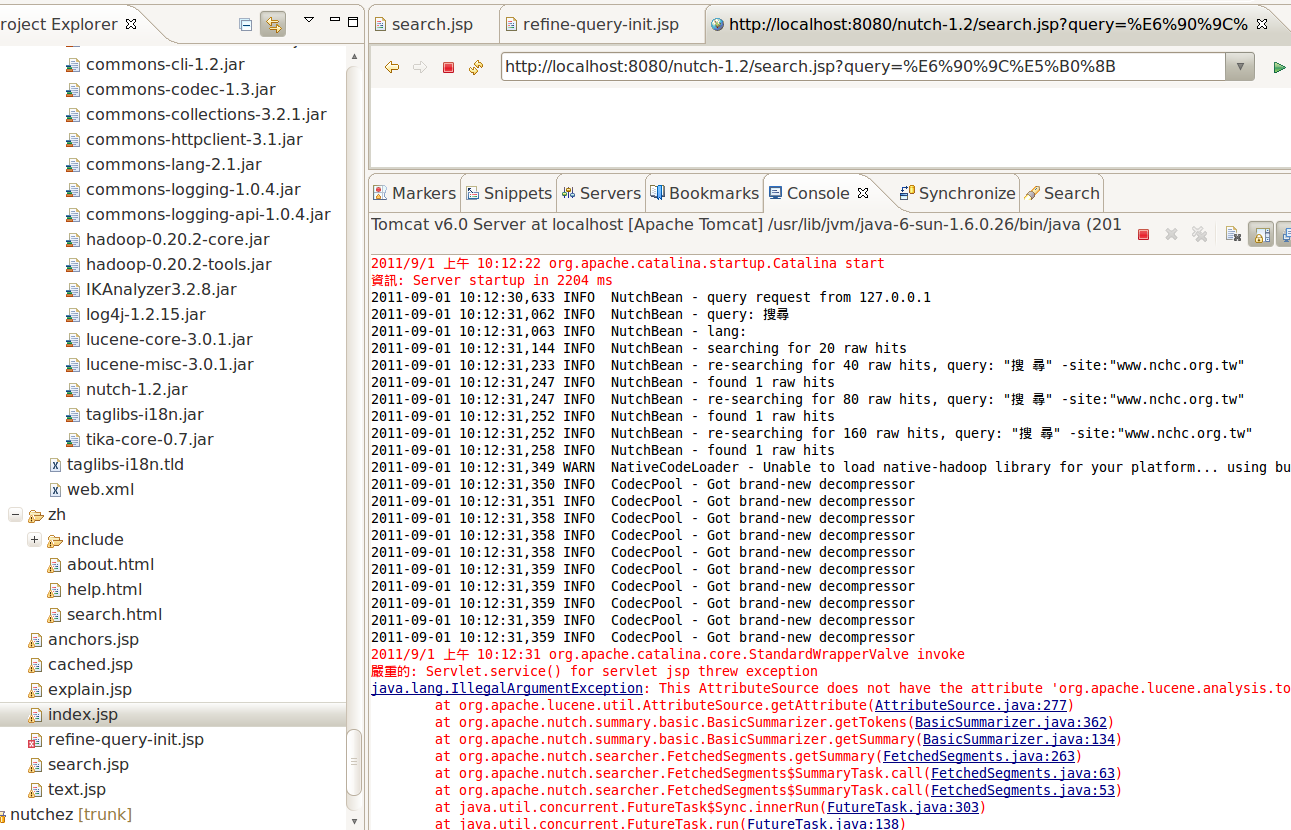
java.lang.RuntimeException?: java.util.concurrent.ExecutionException?: java.lang.StringIndexOutOfBoundsException?: String index out of range: -4 at org.apache.nutch.searcher.FetchedSegments?.getSummary(FetchedSegments?.java:316)
修改:
nutch/src/plugin/summary-basic/src/java/org/apache/nutch/summary/basic/BasicSummarizer.java
...(no. 181)... // fix begin Token t = tokens[j]; if (highlight.contains(t.term())) { excerpt.addToken(t.term()); if( offset < t.startOffset() ){ excerpt.add(new Fragment(text.substring(offset, t.startOffset()))); excerpt.add(new Highlight(text.substring(t.startOffset(),t.endOffset()))); } if( offset >= t.startOffset() ){ if( offset < t.endOffset() ){ excerpt.add(new Highlight(text.substring(offset,t.endOffset()))); } } offset = Math.max(offset, t.endOffset()); endToken = Math.min(j + sumContext, tokens.length); } j++; } //while // fix over
...(no. 181)... if(j<tokens.length){ if(offset< tokens[j].endOffset()){ excerpt.add(new Fragment(text.substring(offset,tokens[j].endOffset()))); } }
- 重新編譯 nutch 並產生 nutch-job-1.2.job
ant
- build/ nutch-job-1.2.job 就是重編後的核心
ant jar; ant war;
- build/ nutch-job-1.2.jar 工作函式庫
佈署
分別將 IKAnalyzer3.2.8-waue.jar(fixed) ; nutch-1.2.jar ; nutch-1.2.job 放到以下目錄
目錄 放置檔案 /opt/crawlzilla/nutch/lib/ IKAnalyzer3.2.8-waue.jar /opt/crawlzilla/nutch nutch-1.2.jar
nutch-1.2.job/opt/crawlzilla/tomcat/webapps/default/WEB-INF/lib/ IKAnalyzer3.2.8-waue.jar
nutch-1.2.jar
- 最後用nutch 的 crawl 抓取網頁,搜索的結果就是按ik分過的中文詞
- 不使用修正過後的IK分詞庫,雖然nutch 爬取沒問題,也能建立正確的分詞庫,但索引網頁return 回來的頁面會是空白一片,可參考Debug 一節
修改
修改Nutch 搜尋頁面參考
Debug
crawlzilla 搜尋結果只會出現空白一片
crawlzilla 搜尋 解析 ok ,但搜尋 解析度 則出現錯誤
補充
選項:加入字典檔
- 編輯 IKAnalyzer.cfg.xml
<properties>
<comment>IK Analyzer</comment> <entry key="ext_dict">/cyc.dic</entry>
</properties>
- 編輯你的字典檔 cyc.dic ,一行一個關鍵字,如:
數學 嘉義縣網
- 用解壓縮工具打開 /opt/crawlzilla/nutch/nutch-1.2.job,塞入 cyc.dic 與 IKAnalyzer.cfg.xml
- 重新啟動crawlzilla 的所有服務
之後抓的索引庫就有該中文分詞了了
補充: 如果有兩個字典檔以上的話,可以一起放到 nutch-1.0.job 的壓縮檔內, 修改 IKAnalyzer.cfg.xml ,加入字典檔, 每個字典檔各用分號區隔。 如
<entry key="ext_dict">/cyc.dic;/cyc2.dic</entry>
Attachments (5)
- 1.png (308.2 KB) - added by waue 15 years ago.
- 3-1.png (201.5 KB) - added by waue 15 years ago.
- 3-2.png (225.3 KB) - added by waue 15 years ago.
- IKAnalyzer3.2.8_waue.jar (1.1 MB) - added by waue 15 years ago.
- 2.png (266.3 KB) - added by waue 15 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}