
| Version 8 (modified by waue, 17 years ago) (diff) |
|---|
Nutch 完整攻略
前言
- 雖然之前已經測試過了,網路上也有許多人分享過成功的經驗,然而這篇的重點
- 完整的安裝nutch,並解決中文亂碼問題
- 用hadoop的角度來架設nutch
- 搜尋引擎不只是找網頁內的資料,也能爬到網頁內的檔案(如pdf,msword)
環境
- 目錄
| /opt/nutch | nutch 家目錄 |
| /opt/nutch_conf | nutch設定檔 |
| /opt/hadoop | hadoop家目錄 |
| /opt/hadoop/conf | hadoop設定檔 |
step 1 安裝好Hadoop
可以用實做一的方法來安裝,然而為了簡化Hadoop安裝,用最簡方式實做
~$ cd /opt/ ~$ wget http://hadoop.nchc.org.tw/~waue/hadoop_nchc.tar.gz ~$ tar -zxvf hadoop_nchc.tar.gz ~$ chown -R hadooper hadoop ~$ cd /opt/hadoop ~$ bin/hadoop namenode -format ~$ bin/start-all
step 2 下載與安裝
2.1 下載 nutch 並解壓縮
- nutch 1.0 (2009/03/28 release )
$ cd /opt $ wget http://ftp.twaren.net/Unix/Web/apache/lucene/nutch/nutch-1.0.tar.gz $ tar -zxvf nutch-1.0.tar.gz $ mv nutch-1.0 nutch
2.2 部屬hadoop,nutch目錄結構
$ cp -rf hadoop/* nutch $ cd nutch
step 3 編輯設定檔
- 所有的設定檔都在 /opt/nutch/conf 下
3.1 hadoop-env.sh
- 將原本的檔案hadoop-env.sh任意處填入
export JAVA_HOME=/usr/lib/jvm/java-6-sun export HADOOP_HOME=/opt/nutch export HADOOP_CONF_DIR=/opt/nutch/conf export HADOOP_SLAVES=$HADOOP_CONF_DIR/slaves export HADOOP_LOG_DIR=/tmp/hadoop/logs export HADOOP_PID_DIR=/tmp/hadoop/pid export NUTCH_HOME=/opt/nutch export NUTCH_CONF_DIR=/opt/nutch/conf
- 載入環境設定值
$ source /opt/nutch/conf/hadoop-env.sh
- ps:強烈建議寫入 /etc/bash.bashrc 中比較萬無一失!!
3.3 conf/nutch-site.xml
- 重要的設定檔,新增了必要的內容於內,然而想要瞭解更多參數資訊,請見nutch-default.xml
$ vim conf/nutch-site.xml
<configuration> <property> <name>http.agent.name</name> <value>nutch</value> <description>HTTP 'User-Agent' request header. </description> </property> <property> <name>http.agent.description</name> <value>nutch-crawl</value> <description>Further description</description> </property> <property> <name>http.agent.url</name> <value>localhost</value> <description>A URL to advertise in the User-Agent header. </description> </property> <property> <name>http.agent.email</name> <value>user@nchc.org.tw</value> <description>An email address </description> </property> <property> <name>plugin.folders</name> <value>/opt/nutch/plugins</value> <description>Directories where nutch plugins are located. </description> </property> <property> <name>plugin.includes</name> <value>protocol-(http|httpclient)|urlfilter-regex|parse-(text|html|js|ext|msexcel|mspowerpoint|msword|oo|pdf|rss|swf|zip)|index-(more|basic|anchor)|query-(more|basic|site|url)|response-(json|xml)|summary-basic|scoring-opic|urlnormalizer-(pass|regex|basic)</value> <description> Regular expression naming plugin directory names</description> </property> <property> <name>parse.plugin.file</name> <value>parse-plugins.xml</value> <description>The name of the file that defines the associations between content-types and parsers.</description> </property> <property> <name>db.max.outlinks.per.page</name> <value>-1</value> <description> </description> </property> <property> <name>http.content.limit</name> <value>-1</value> </property> <property> <property> <name>indexer.mergeFactor</name> <value>500</value> <description>The factor that determines the frequency of Lucene segment merges. </description> </property> <property> <name>indexer.minMergeDocs</name> <value>500</value> <description>This number determines the minimum number of Lucene. </description> </property> </configuration>
3.5 crawl-urlfilter.txt
- 重新編輯爬檔規則,此檔重要在於若設定不好,則爬出來的結果幾乎是空的,也就是說最後你的搜尋引擎都找不到資料啦!
$ vim conf/crawl-urlfilter.txt
# skip ftp:, & mailto: urls -^(ftp|mailto): # skip image and other suffixes we can't yet parse -\.(gif|GIF|jpg|JPG|png|PNG|ico|ICO|css|sit|eps|wmf|mpg|xls|gz|rpm|tgz|mov|MOV|exe|jpeg|JPEG|bmp|BMP)$ # skip URLs containing certain characters as probable queries, etc. -[*!@] # accecpt anything else +.*
step 4 執行nutch
4.1 編輯url清單
$ mkdir urls $ echo "http://www.nchc.org.tw" >> ./urls/urls.txt
4.2 上傳清單到HDFS
$ bin/hadoop dfs -put urls urls
4.3 執行nutch crawl
- 用下面的指令就可以命令nutch開始工作了,之後map reduce會瘋狂工作
$ bin/nutch crawl urls -dir search -threads 2 -depth 3 -topN 100000
- 執行上個指令會把執行過程秀在stdout上。若想要以後慢慢看這些訊息,可以用io導向的方式傾倒於日誌檔
$ bin/nutch crawl urls -dir search -threads 2 -depth 3 -topN 100000 >& nutch.log
- 執行上個指令會把執行過程秀在stdout上。若想要以後慢慢看這些訊息,可以用io導向的方式傾倒於日誌檔
- 在nutch運作的同時,可以在node1節點用瀏覽器,透過 job管理頁面,hdfs管理頁面,程序運作頁面 來監看程序。
step 5 瀏覽搜尋結果
- nutch 在 step 4 的工作是把你寫在urls.txt檔內的網址,用map reduce的程序來進行資料分析,但是分析完之後,要透過tomcat來觀看結果。以下就是安裝與設定你的客製化搜尋引擎的步驟。
5.1 安裝tomcat
- 下載tomcat
$ cd /opt/ $ wget http://ftp.twaren.net/Unix/Web/apache/tomcat/tomcat-6/v6.0.18/bin/apache-tomcat-6.0.18.tar.gz
- 解壓縮
$ tar -xzvf apache-tomcat-6.0.18.tar.gz $ mv apache-tomcat-6.0.18 tomcat
5.1 tomcat server設定
- 修改 /opt/tomcat/conf/server.xml 以修正中文亂碼問題
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8" useBodyEncodingForURI="true" />
5.3 下載crawl結果
- 先把放在hdfs上,nutch的運算結果下載到local端
$ cd /opt/nutch $ bin/hadoop dfs -get search /opt/search
5.4 設定nutch的搜尋引擎頁面到tomcat
- 把nutch的搜尋引擎頁面取代為tomcat的webapps/ROOT
$ cd /opt/nutch $ mkdir web $ cd web $ jar -xvf nutch-1.0.war $ rm nutch-1.0.war $ mv /opt/tomcat/webapps/ROOT /opt/tomcat/webapps/ROOT-ori $ cd /opt/nutch $ mv /opt/nutch/web /opt/tomcat/webapps/ROOT
5.5 設定搜尋引擎內容的來源路徑
- 5.4的步驟雖然設定好搜尋引擎的頁面,然而其只能當作是介面而已,因此這個步驟把要搜尋的內容與搜尋介面做個連結
$ vim /opt/tomcat/webapps/ROOT/WEB-INF/classes/nutch-site.xml
<configuration>
<property>
<name>searcher.dir</name>
<value>/opt/search</value>
</property>
</configuration>
5.6 啟動tomcat
$ /opt/tomcat/bin/startup.sh
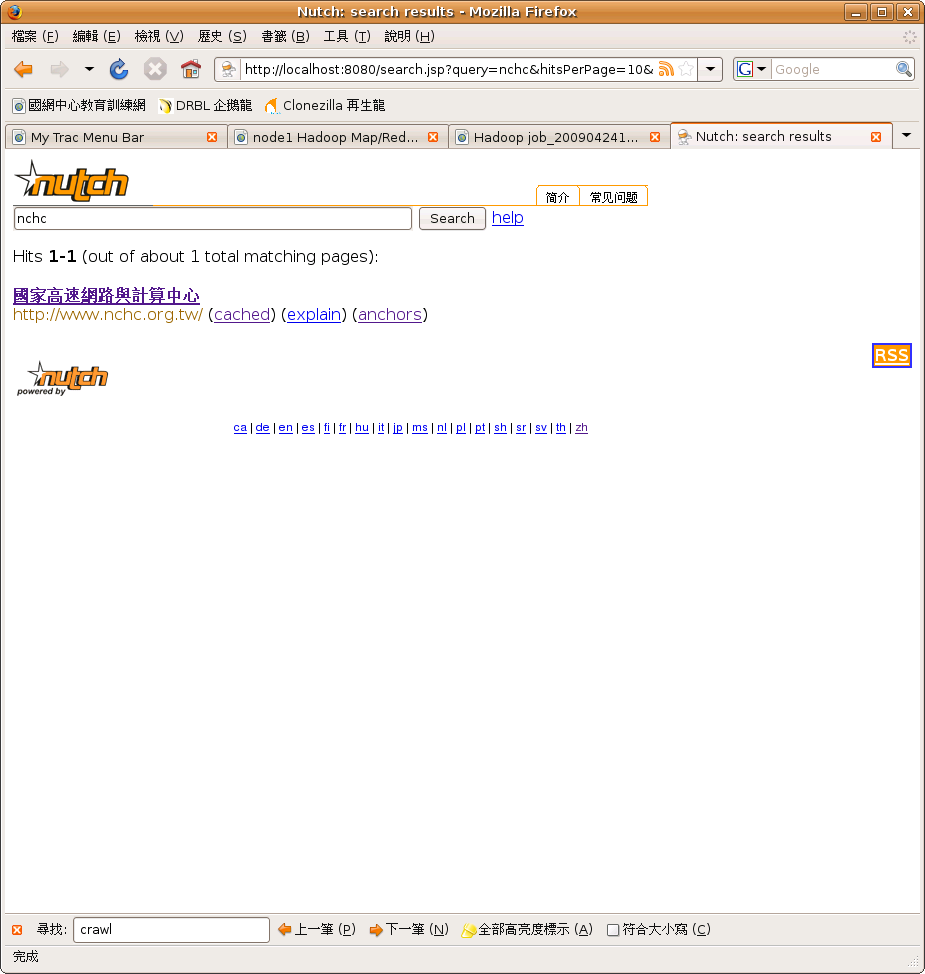
step 6 享受結果
Enjoy ! http://localhost:8080
Attachments (1)
- 1.png (55.7 KB) - added by waue 17 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip