
Nutch 安裝使用
前言
- 做完之前的實做,已經對hadoop有一定的體驗,然而各位也許心中有些疑問,就是我學了hadoop到底可以用來..?,因此在此介紹一個hadoop的應用,搜尋引擎nutch
- 此篇的重點在於
- 完整的安裝nutch
- 用hadoop的角度來架設nutch
- 解決中文亂碼問題
- 搜尋引擎不只是找網頁內的資料,也能爬到網頁內的檔案(如pdf,msword)
- 也可運行在多台node
環境
- 目錄
| /opt/nutch | nutch 家目錄 |
| /opt/nutch/conf | nutch設定檔 |
| /opt/hadoop | hadoop家目錄 |
| /opt/hadoop/conf | hadoop設定檔 |
step 1 安裝好Hadoop
單機版
可以用實做一的方法來安裝單機
- 執行
~$ cd /opt /opt$ sudo wget http://ftp.twaren.net/Unix/Web/apache/hadoop/core/hadoop-0.18.3/hadoop-0.18.3.tar.gz /opt$ sudo tar zxvf hadoop-0.18.3.tar.gz /opt$ sudo mv hadoop-0.18.3/ hadoop /opt$ sudo chown -R hadooper:hadooper hadoop /opt$ cd hadoop/ /opt/hadoop$ gedit conf/hadoop-env.sh
在任一行內貼上
export JAVA_HOME=/usr/lib/jvm/java-6-sun export HADOOP_HOME=/opt/hadoop export HADOOP_CONF_DIR=/opt/hadoop/conf export HADOOP_LOG_DIR=/tmp/hadoop/logs export HADOOP_PID_DIR=/tmp/hadoop/pid
- 執行
/opt/hadoop$ gedit conf/hadoop-site.xml
用以下內容取代整個檔案
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000/</value>
<description> </description>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
<description> </description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop/hadoop-${user.name}</value>
<description> </description>
</property>
</configuration>
- 接著執行
/opt/hadoop$ bin/hadoop namenode -format /opt/hadoop$ bin/start-all.sh
- 啟動之後,可以檢查以下網址,來觀看服務是否正常。Hadoop 管理介面 Hadoop Task Tracker 狀態 Hadoop DFS 狀態
叢集版
請參考實作三
step 2 nutch下載與安裝
2.0 設定環境
- 系統環境變數內加入java_home的路徑
$ sudo su - # echo "export JAVA_HOME=/usr/lib/jvm/java-6-sun" >> /etc/bash.bashrc # chown -R hadooper /opt # exit # exit
- 停止原本的hadoop
$ cd /opt/hadoop $ bin/stop-all.sh
2.1 下載 nutch 並解壓縮
- nutch 1.0 (2009/03/28 release )
$ cd /opt $ wget http://ftp.twaren.net/Unix/Web/apache/lucene/nutch/nutch-1.0.tar.gz $ tar -zxvf nutch-1.0.tar.gz $ mv nutch-1.0 nutch
2.2 部屬hadoop,nutch目錄結構
$ cp -rf /opt/hadoop/* /opt/nutch
2.3 複製函式庫檔
$ cd nutch $ cp -rf *.jar lib/
step 3 編輯設定檔
- 所有的設定檔都在 /opt/nutch/conf 下
3.1 $NUTCH_HOME/conf/hadoop-env.sh
$ cd /opt/nutch/conf $ gedit hadoop-env.sh
- 將找到原本再hadoop-env.sh的設定,將之改成以下設定
export JAVA_HOME=/usr/lib/jvm/java-6-sun export HADOOP_HOME=/opt/nutch export HADOOP_CONF_DIR=/opt/nutch/conf export HADOOP_SLAVES=$HADOOP_CONF_DIR/slaves export HADOOP_LOG_DIR=/tmp/hadoop/logs export HADOOP_PID_DIR=/tmp/hadoop/pid export NUTCH_HOME=/opt/nutch export NUTCH_CONF_DIR=/opt/nutch/conf
- 載入環境設定值
$ source ./hadoop-env.sh
- ps:強烈建議寫入 /etc/bash.bashrc 中比較萬無一失!!
- 載入環境設定值
3.2 $NUTCH_HOME/conf/nutch-site.xml
- 重要的設定檔,新增了必要的內容於內,然而想要瞭解更多參數資訊,請見nutch-default.xml
$ gedit nutch-site.xml
<configuration> <property> <name>http.agent.name</name> <value>nutch</value> <description>HTTP 'User-Agent' request header. </description> </property> <property> <name>http.agent.description</name> <value>MyTest</value> <description>Further description</description> </property> <property> <name>http.agent.url</name> <value>localhost</value> <description>A URL to advertise in the User-Agent header. </description> </property> <property> <name>http.agent.email</name> <value>test@test.org.tw</value> <description>An email address </description> </property> <property> <name>plugin.folders</name> <value>/opt/nutch/plugins</value> <description>Directories where nutch plugins are located. </description> </property> <property> <name>plugin.includes</name> <value>protocol-(http|httpclient)|urlfilter-regex|parse-(text|html|js|ext|msexcel|mspowerpoint|msword|oo|pdf|rss|swf|zip)|index-(more|basic|anchor)|query-(more|basic|site|url)|response-(json|xml)|summary-basic|scoring-opic|urlnormalizer-(pass|regex|basic)</value> <description> Regular expression naming plugin directory names</description> </property> <property> <name>parse.plugin.file</name> <value>parse-plugins.xml</value> <description>The name of the file that defines the associations between content-types and parsers.</description> </property> <property> <name>db.max.outlinks.per.page</name> <value>-1</value> <description> </description> </property> <property> <name>http.content.limit</name> <value>-1</value> </property> <property> <name>indexer.mergeFactor</name> <value>500</value> <description>The factor that determines the frequency of Lucene segment merges. This must not be less than 2, higher values increase indexing speed but lead to increased RAM usage, and increase the number of open file handles (which may lead to "Too many open files" errors). NOTE: the "segments" here have nothing to do with Nutch segments, they are a low-level data unit used by Lucene. </description> </property> <property> <name>indexer.minMergeDocs</name> <value>500</value> <description>This number determines the minimum number of Lucene Documents buffered in memory between Lucene segment merges. Larger values increase indexing speed and increase RAM usage. </description> </property> </configuration>
3.3 $NUTCH_HOME/conf/crawl-urlfilter.txt
- 重新編輯爬檔規則,此檔重要在於若設定不好,則爬出來的結果幾乎是空的,也就是說最後你的搜尋引擎都找不到資料啦!
$ gedit ./crawl-urlfilter.txt
# skip ftp:, & mailto: urls -^(ftp|mailto): # skip image and other suffixes we can't yet parse -\.(gif|GIF|jpg|JPG|png|PNG|ico|ICO|css|sit|eps|wmf|mpg|xls|gz|rpm|tgz|mov|MOV|exe|jpeg|JPEG|bmp|BMP)$ # skip URLs containing certain characters as probable queries, etc. -[*!@] # accecpt anything else +.*
3.4 環境若要設定成叢集才要做
- 若是單機版則不用處理此節
- 完全複製到node2
$ ssh node02 "sudo chown hadooper:hadooper /opt" $ scp -r /opt/nutch node02:/opt/
step 4 執行nutch
- 先再/opt/nutch內啟動hadoop
$ cd /opt/nutch $ bin/start-all.sh
- 請到管理頁面看是否正常
4.1 編輯url清單
$ cd /opt/nutch $ mkdir urls $ echo "http://www.nchc.org.tw/tw/" >> ./urls/urls.txt
4.2 上傳清單到HDFS
$ bin/hadoop dfs -put urls urls
4.3 執行nutch crawl
- 用下面的指令就可以命令nutch開始工作了,之後map reduce會瘋狂工作
$ bin/nutch crawl urls -dir search -threads 2 -depth 3 -topN 100000
- 執行上個指令會把執行過程秀在stdout上。若想要以後慢慢看這些訊息,可以用io導向的方式傾倒於日誌檔
$ bin/nutch crawl urls -dir search -threads 2 -depth 3 -topN 100000 >& nutch.log
- 執行上個指令會把執行過程秀在stdout上。若想要以後慢慢看這些訊息,可以用io導向的方式傾倒於日誌檔
- 在nutch運作的同時,可以在node01節點用瀏覽器,透過 job管理頁面,hdfs管理頁面,程序運作頁面 來監看程序。
ps: 重要!!! 如果錯誤訊息出現
Exception in thread "main" java.lang.RuntimeException: java.lang.ClassNotFoundException: org.apache.hadoop.dfs.DistributedFileSystem
則代表之前沒有做此2.2的"複製函式庫檔"的步驟,請將hadoop-0.18.3*.jar 拷貝到lib中再執行一次即可
step 5 瀏覽搜尋結果
- nutch 在 step 4 的工作是把你寫在urls.txt檔內的網址,用map reduce的程序來進行資料分析,但是分析完之後,要透過tomcat來觀看結果。以下就是安裝與設定你的客製化搜尋引擎的步驟。
5.1 安裝tomcat
- 下載tomcat
$ cd /opt/ $ wget http://ftp.twaren.net/Unix/Web/apache/tomcat/tomcat-6/v6.0.18/bin/apache-tomcat-6.0.18.tar.gz
- 解壓縮
$ tar -xzvf apache-tomcat-6.0.18.tar.gz $ mv apache-tomcat-6.0.18 tomcat
5.1 tomcat server設定
- 修改 /opt/tomcat/conf/server.xml 以修正中文亂碼問題
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8" useBodyEncodingForURI="true" />
5.3 下載crawl結果
- 先把放在hdfs上,nutch的運算結果下載到local端
$ cd /opt/nutch $ bin/hadoop dfs -get search /opt/search
5.4 設定nutch的搜尋引擎頁面到tomcat
- 把nutch的搜尋引擎頁面取代為tomcat的webapps/ROOT
$ cd /opt/nutch $ mkdir web $ cd web $ jar -xvf ../nutch-1.0.war $ mv /opt/tomcat/webapps/ROOT /opt/tomcat/webapps/ROOT-ori $ cd /opt/nutch $ mv /opt/nutch/web /opt/tomcat/webapps/ROOT
5.5 設定搜尋引擎內容的來源路徑
- 5.4的步驟雖然設定好搜尋引擎的頁面,然而其只能當作是介面而已,因此這個步驟把要搜尋的內容與搜尋介面做個連結
$ gedit /opt/tomcat/webapps/ROOT/WEB-INF/classes/nutch-site.xml
<configuration>
<property>
<name>searcher.dir</name>
<value>/opt/search</value>
</property>
</configuration>
5.6 啟動tomcat
$ /opt/tomcat/bin/startup.sh
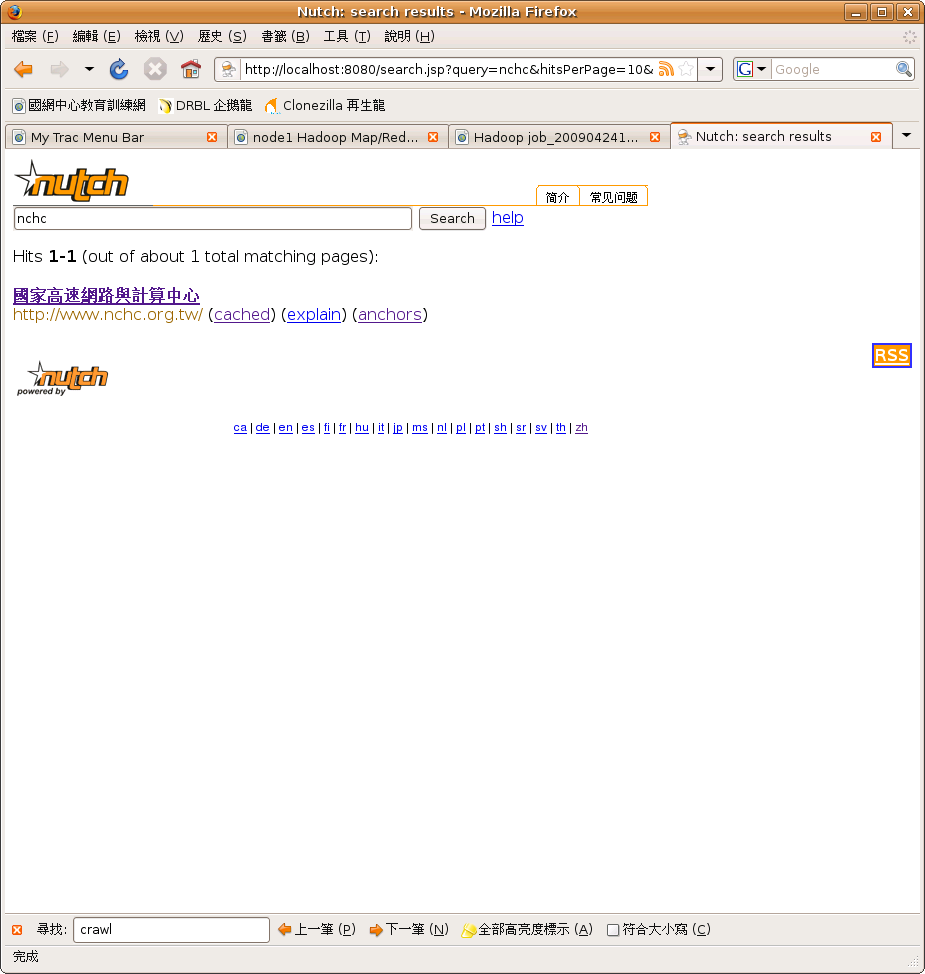
step 6 享受結果
Enjoy ! http://localhost:8080

Last modified 17 years ago
Last modified on Aug 28, 2009, 6:25:49 PM
Attachments (1)
- 1.png (55.7 KB) - added by waue 17 years ago.
{kind=link}
Download all attachments as: .zip