
零. 前言
- 開發hadoop 需要用到許多的物件導向語法,包括繼承關係、介面類別,而且需要匯入正確的classpath,否則寫hadoop程式只是打字練習...
- 用類 vim 來處理這種複雜的程式,有可能會變成一場惡夢,因此用eclipse開發,搭配mapreduce-plugin會事半功倍。
- 早在hadoop 0.19~0.16之間的版本,筆者就試過各個plugin,每個版本的plugin都確實有大大小小的問題,如:hadoop plugin 無法正確使用、無法run as mapreduce。hadoop0.16搭配IBM的hadoop_plugin 可以提供完整的功能,但是,老兵不死,只是凋零...
- 子曰:"逝者如斯夫,不捨晝夜",以前寫的文件也落伍了,要跟上潮流,因此此篇的重點在:用eclipse 3.4.2 開發hadoop 0.20程式,並且測試撰寫的程式運作在hadoop平台上
- 以下是我的作法,如果你有更好的作法,或有需要更正的地方,請與我聯絡
單位 作者 國家高速網路中心-格網技術組 Wei-Yu Chen waue @ nchc.org.tw
0.0 Info Update
- Last Update: 2010/01/22
最新版本的 Eclipse 3.5 搭配 Ubuntu 9.04 + hadoop-eclipse-plugin 0.20.1 ,初步測試功能皆可正常運作
但 Ubuntu 9.10 的 各版本 Eclipse , 似乎會有 gtk 圖形介面的bug ,有此一說增加 GDK_NATIVE_WINDOWS=1 就可以解決問題,但經過初步測試似乎無用
0.1 環境說明
- ubuntu 8.10
- sun-java-6
- eclipse 3.4.2
- hadoop 0.20.0
0.2 目錄說明
- 使用者:waue
- 使用者家目錄: /home/waue
- 專案目錄 : /home/waue/workspace
- hadoop目錄: /opt/hadoop
一、安裝
安裝的部份沒必要都一模一樣,僅提供參考,反正只要安裝好java , hadoop , eclipse,並清楚自己的路徑就可以了
1.1. 安裝java
首先安裝java 基本套件
$ sudo apt-get install java-common sun-java6-bin sun-java6-jdk sun-java6-jre
1.1.1. 安裝sun-java6-doc
1 將javadoc (jdk-6u10-docs.zip) 下載下來 下載點


2 下載完後將檔案放在 /tmp/ 下
3 執行
$ sudo apt-get install sun-java6-doc
1.2. ssh 安裝設定
$ apt-get install ssh $ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ ssh localhost
執行ssh localhost 沒有出現詢問密碼的訊息則無誤
1.3. 安裝hadoop
安裝hadoop0.20到/opt/並取目錄名為hadoop
$ cd ~ $ wget http://apache.ntu.edu.tw/hadoop/core/hadoop-0.20.0/hadoop-0.20.0.tar.gz $ tar zxvf hadoop-0.20.0.tar.gz $ sudo mv hadoop-0.20.0 /opt/ $ sudo chown -R waue:waue /opt/hadoop-0.20.0 $ sudo ln -sf /opt/hadoop-0.20.0 /opt/hadoop
- 編輯 /opt/hadoop/conf/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-6-sun export HADOOP_HOME=/opt/hadoop export PATH=$PATH:/opt/hadoop/bin
- 編輯 /opt/hadoop/conf/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop/hadoop-${user.name}</value>
</property>
</configuration>
- 編輯 /opt/hadoop/conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- 編輯 /opt/hadoop/conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
- 啟動
$ cd /opt/hadoop $ source /opt/hadoop/conf/hadoop-env.sh $ hadoop namenode -format $ start-all.sh $ hadoop fs -put conf input $ hadoop fs -ls
- 沒有錯誤訊息則代表無誤
1.4. 安裝eclipse
- 在此提供兩個方法來下載檔案
- 方法一:下載 eclipse SDK 3.4.2 Classic,並且放這檔案到家目錄
- 方法二:貼上指令
$ cd ~ $ wget http://ftp.cs.pu.edu.tw/pub/eclipse/eclipse/downloads/drops/R-3.4.2-200902111700/eclipse-SDK-3.4.2-linux-gtk.tar.gz
- eclipse 檔已下載到家目錄後,執行下面指令:
$ cd ~ $ tar -zxvf eclipse-SDK-3.4.2-linux-gtk.tar.gz $ sudo mv eclipse /opt $ sudo ln -sf /opt/eclipse/eclipse /usr/local/bin/
二、 建立專案
2.1 安裝hadoop 的 eclipse plugin
- 匯入hadoop 0.20.0 eclipse plugin
$ cd /opt/hadoop $ sudo cp /opt/hadoop/contrib/eclipse-plugin/hadoop-0.20.0-eclipse-plugin.jar /opt/eclipse/plugins
$ sudo vim /opt/eclipse/eclipse.ini
- 可斟酌參考eclipse.ini內容(非必要)
-startup plugins/org.eclipse.equinox.launcher_1.0.101.R34x_v20081125.jar --launcher.library plugins/org.eclipse.equinox.launcher.gtk.linux.x86_1.0.101.R34x_v20080805 -showsplash org.eclipse.platform --launcher.XXMaxPermSize 512m -vmargs -Xms40m -Xmx512m
2.2 開啟eclipse
- 打開eclipse
$ eclipse &
一開始會出現問你要將工作目錄放在哪裡:在這我們用預設值

PS: 之後的說明則是在eclipse 上的介面操作
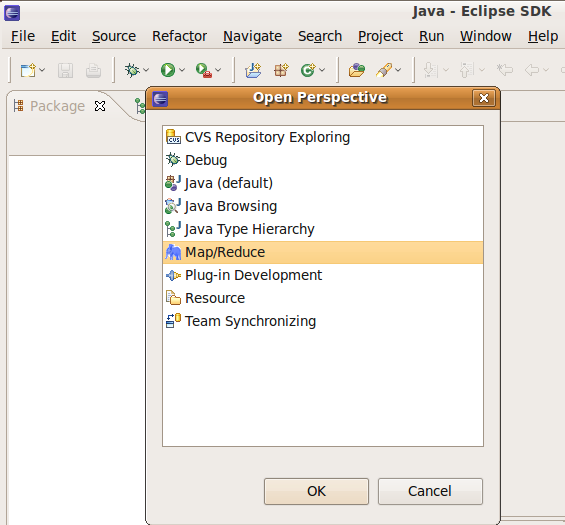
2.3 選擇視野
| window -> | open pers.. -> | other.. -> | map/reduce |

設定要用 Map/Reduce? 的視野

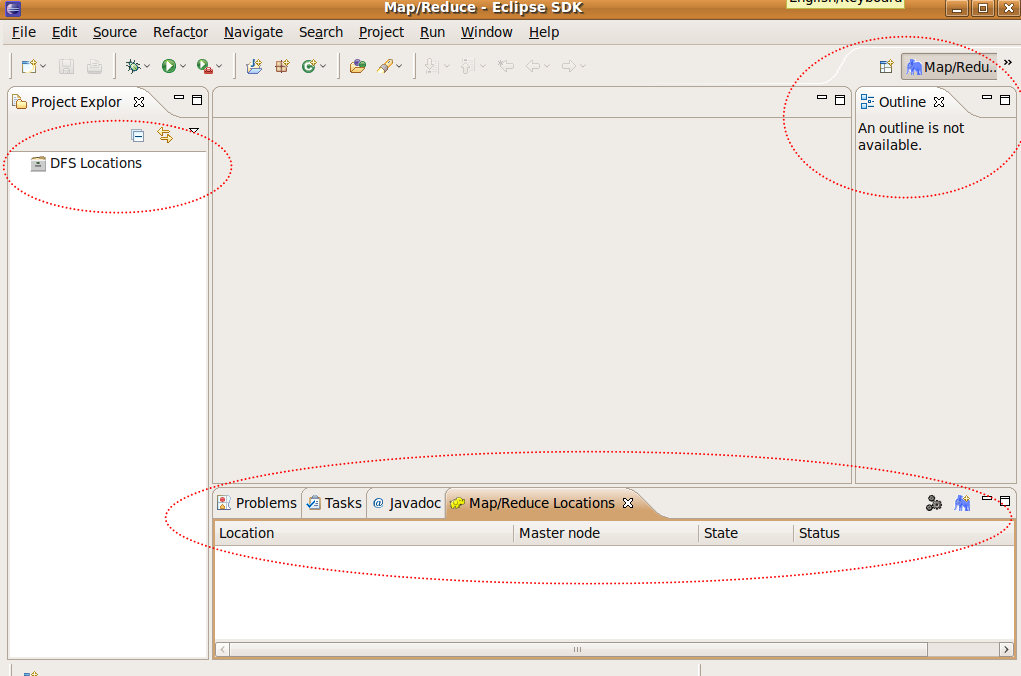
使用 Map/Reduce? 的視野後的介面呈現

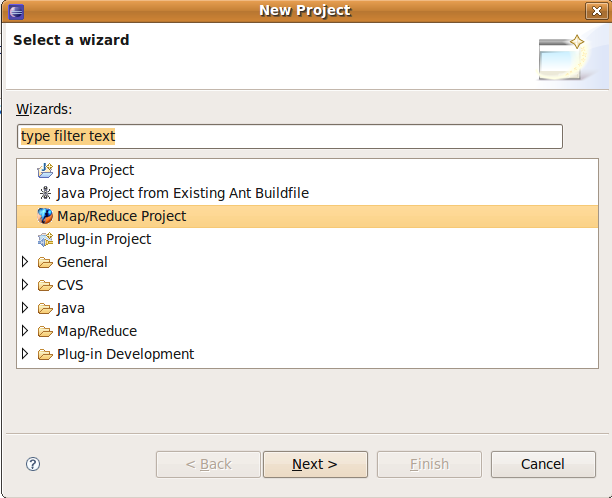
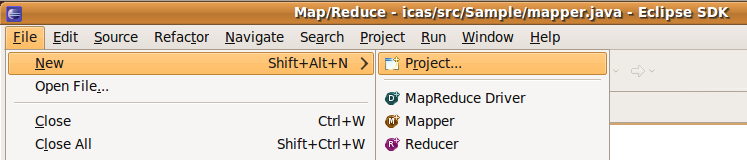
2.4 建立專案
file -> new -> project -> Map/Reduce? -> Map/Reduce? Project -> next

建立mapreduce專案(1)

建立mapreduce專案的(2)
project name-> 輸入 : icas (隨意) use default hadoop -> Configur Hadoop install... -> 輸入: "/opt/hadoop" -> ok Finish

2.5 設定專案
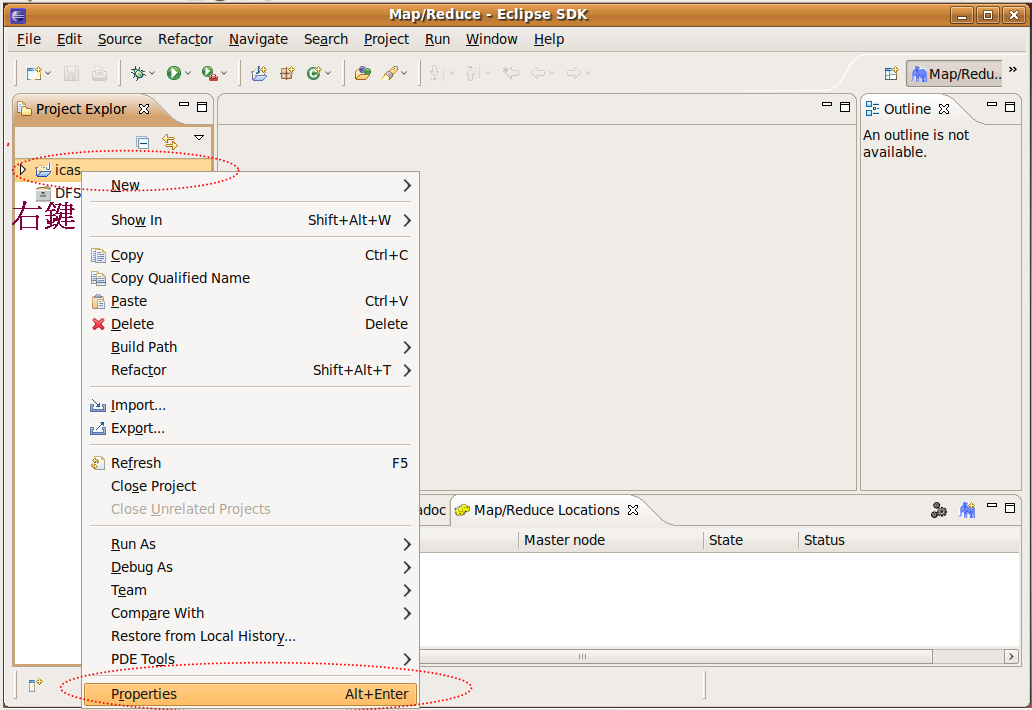
由於剛剛建立了icas這個專案,因此eclipse已經建立了新的專案,出現在左邊視窗,右鍵點選該資料夾,並選properties
Step1. 右鍵點選project的properties做細部設定

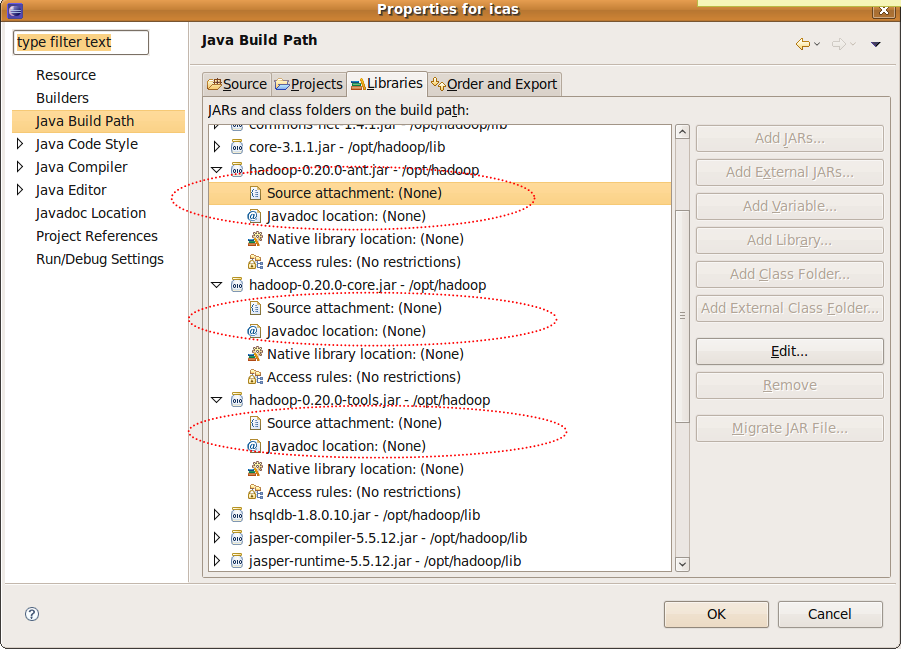
Step2. 進入專案的細部設定頁
hadoop的javadoc的設定(1)

- java Build Path -> Libraries -> hadoop-0.20.0-ant.jar
- java Build Path -> Libraries -> hadoop-0.20.0-core.jar
- java Build Path -> Libraries -> hadoop-0.20.0-tools.jar
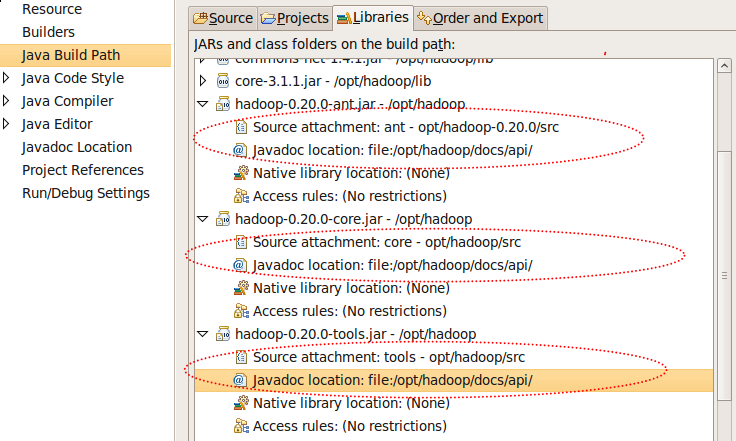
- 以 hadoop-0.20.0-core.jar 的設定內容如下,其他依此類推
source ...-> 輸入:/opt/opt/hadoop-0.20.0/src
javadoc ...-> 輸入:file:/opt/hadoop/docs/api/
Step3. hadoop的javadoc的設定完後(2)

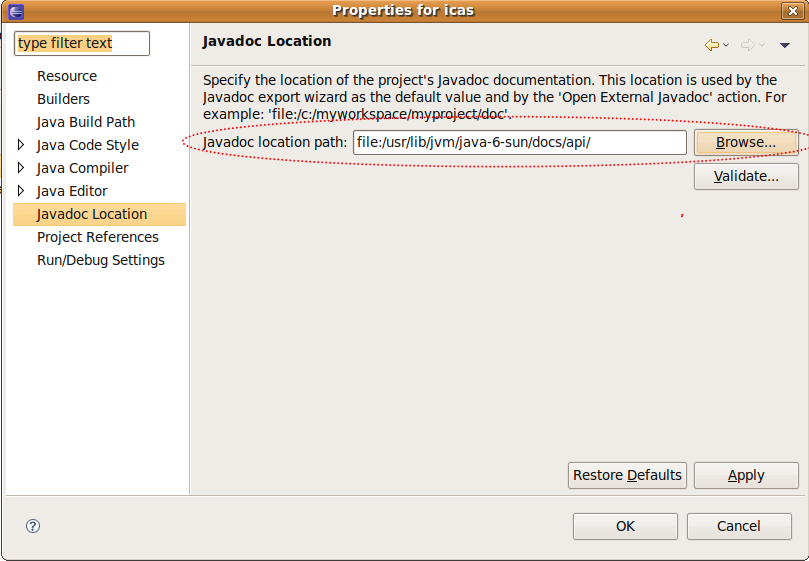
Step4. java本身的javadoc的設定(3)
- javadoc location -> 輸入:file:/usr/lib/jvm/java-6-sun/docs/api/

設定完後回到eclipse 主視窗
2.6 連接hadoop server
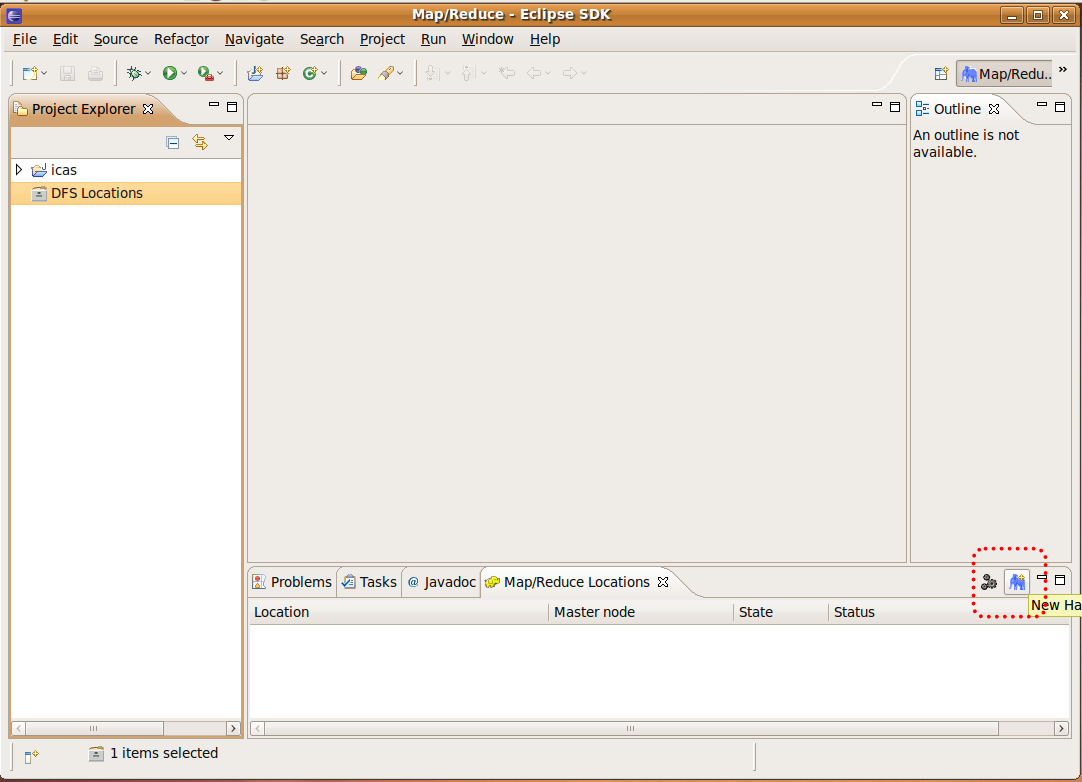
Step1. 視窗右下角黃色大象圖示"Map/Reduce? Locations tag" -> 點選齒輪右邊的藍色大象圖示:

Step2. 進行eclipse 與 hadoop 間的設定(2)

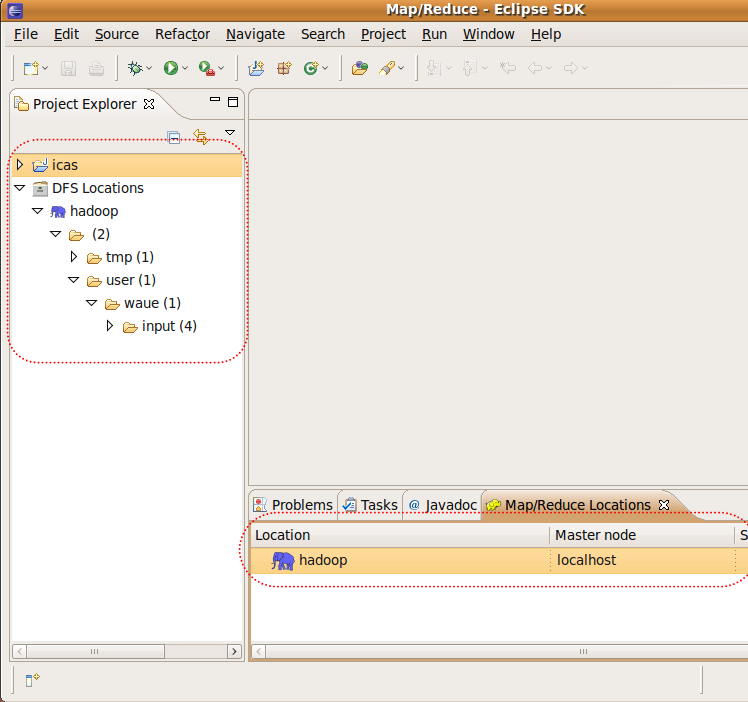
Location Name -> 輸入:hadoop (隨意) Map/Reduce Master -> Host-> 輸入:localhost Map/Reduce Master -> Port-> 輸入:9001 DFS Master -> Host-> 輸入:9000 Finish
設定完後,可以看到下方多了一隻藍色大象,左方展開資料夾也可以秀出在hdfs內的檔案結構

三、 撰寫範例程式
- 之前在eclipse上已經開了個專案icas,因此這個目錄在:
- /home/waue/workspace/icas
- 在這個目錄內有兩個資料夾:
- src : 用來裝程式原始碼
- bin : 用來裝編譯後的class檔
- 如此一來原始碼和編譯檔就不會混在一起,對之後產生jar檔會很有幫助
- 在這我們編輯一個範例程式 : WordCount
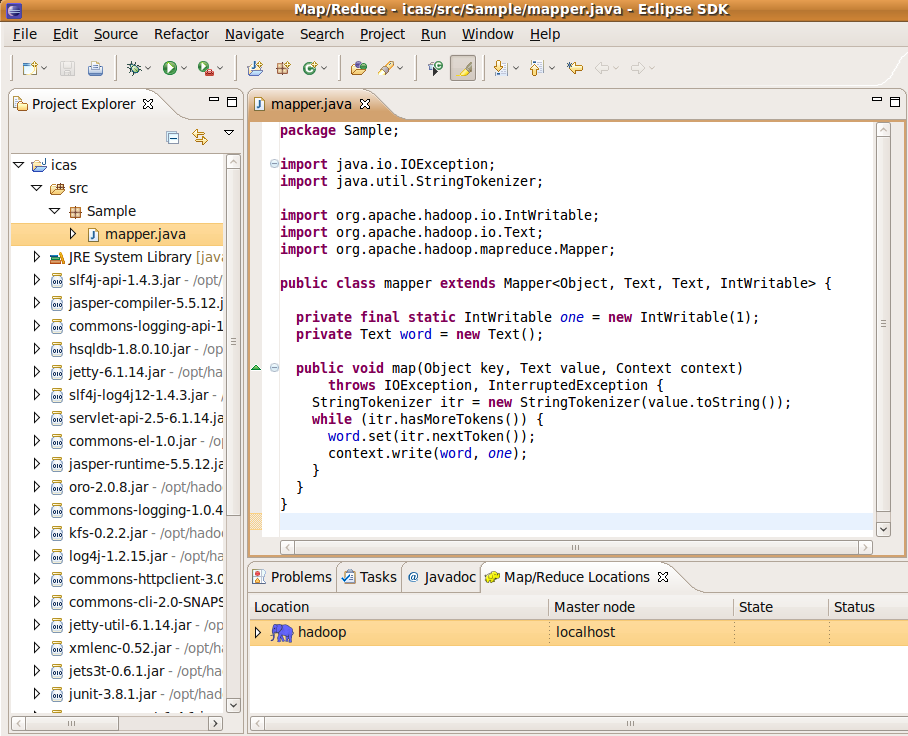
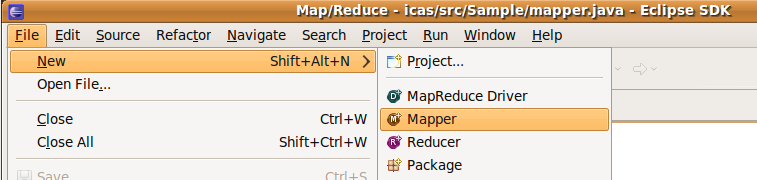
3.1 mapper.java
- new
File -> new -> mapper

- create

source folder-> 輸入: icas/src
Package : Sample
Name -> : mapper
- modify
package Sample; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class mapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
建立mapper.java後,貼入程式碼

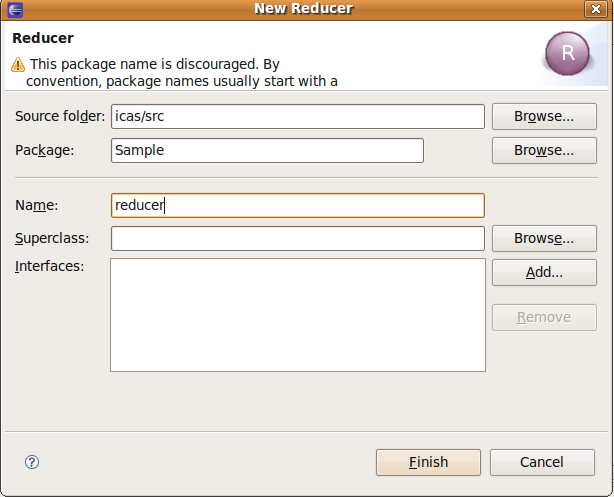
3.2 reducer.java
- new
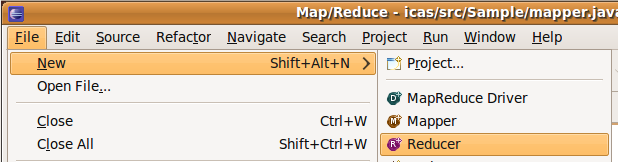
- File -> new -> reducer

- create

source folder-> 輸入: icas/src
Package : Sample
Name -> : reducer
- modify
package Sample; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class reducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
- File -> new -> Map/Reduce? Driver

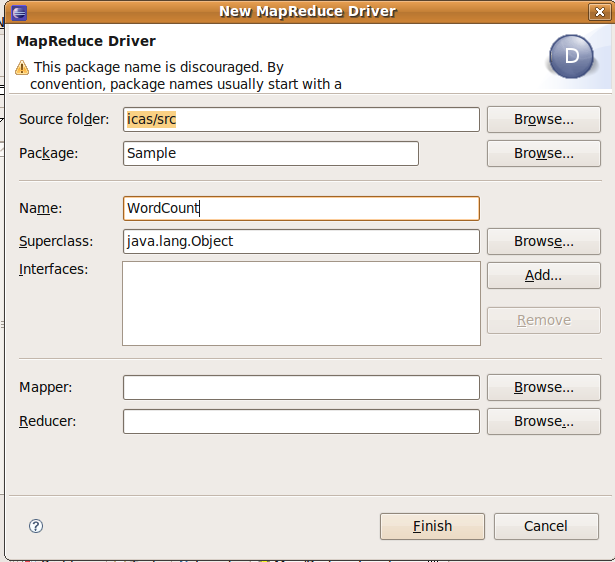
3.3 WordCount.java (main function)
- new
建立WordCount.java,此檔用來驅動mapper 與 reducer,因此選擇 Map/Reduce? Driver

- create
source folder-> 輸入: icas/src
Package : Sample
Name -> : WordCount.java
- modify
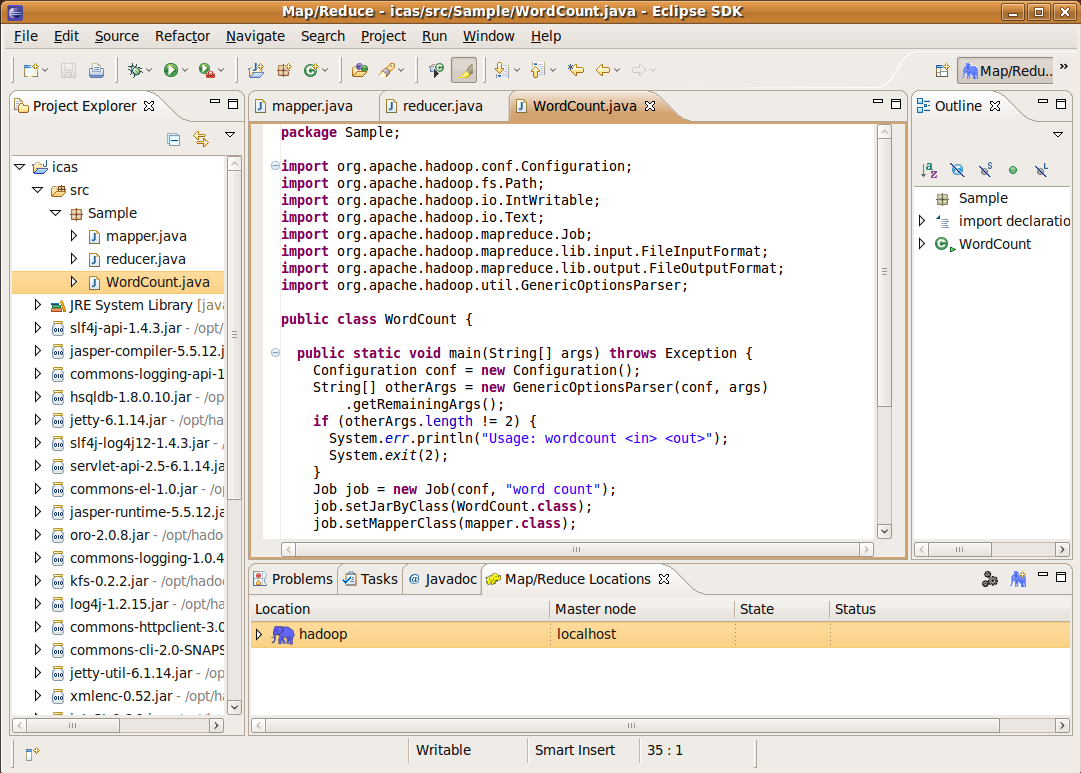
package Sample; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(mapper.class); job.setCombinerClass(reducer.class); job.setReducerClass(reducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
三個檔完成後並存檔後,整個程式建立完成

- 三個檔都存檔後,可以看到icas專案下的src,bin都有檔案產生,我們用指令來check
$ cd workspace/icas $ ls src/Sample/ mapper.java reducer.java WordCount.java $ ls bin/Sample/ mapper.class reducer.class WordCount.class
四、測試範例程式
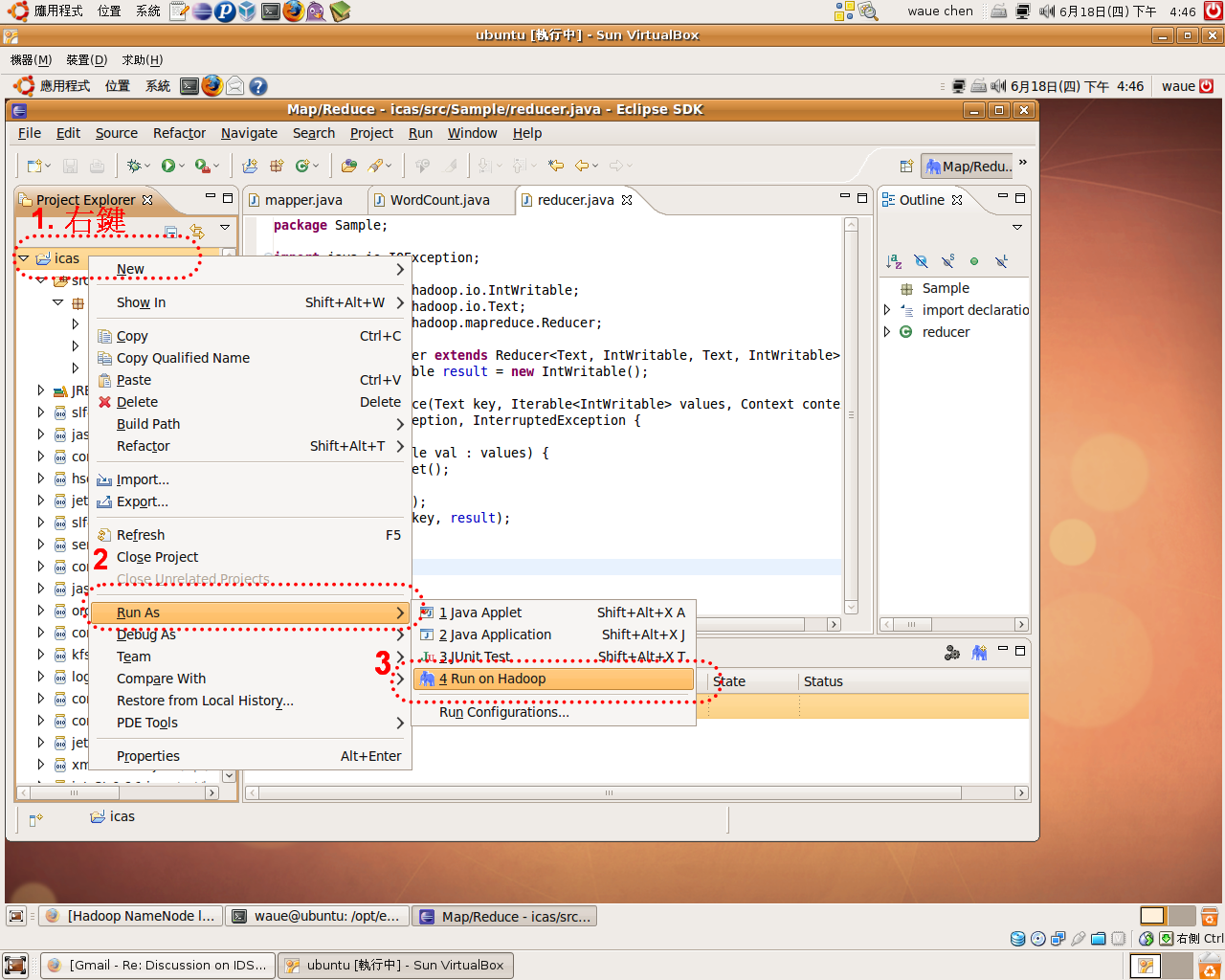
- 由於hadoop 0.20 此版本的eclipse-plugin依舊不完整 ,如:
- 右鍵點選WordCount.java -> run as -> run on Hadoop :沒有效果

- 因此,4.1 提供一個eclipse 上解除 run-on-hadoop 封印的方法。而4.2 則是避開run-on-hadoop 這個功能,用command mode端指令的方法執行。
4.1 解除run-on-hadoop封印
有一熱心的hadoop使用者提供一個能讓 run-on-hadoop 這個功能恢復的方法。
原因是hadoop 的 eclipse-plugin 也許是用eclipse europa 這個版本開發的,而eclipse 的各版本 3.2 , 3.3, 3.4 間也都有或多或少的差異性存在。
因此如果先用eclipse europa 來建立一個新專案,之後把europa的eclipse這個版本關掉,換用eclipse 3.4開啟,之後這個專案就能用run-on-mapreduce 這個功能囉!
有興趣的話可以試試!(感謝逢甲資工所謝同學)
4.2 運用終端指令
4.2.1 產生Makefile 檔
$ cd /home/waue/workspace/icas/ $ gedit Makefile
- 輸入以下Makefile的內容
JarFile="sample-0.1.jar" MainFunc="Sample.WordCount" LocalOutDir="/tmp/output" all:help jar: jar -cvf ${JarFile} -C bin/ . run: hadoop jar ${JarFile} ${MainFunc} input output clean: hadoop fs -rmr output output: rm -rf ${LocalOutDir} hadoop fs -get output ${LocalOutDir} gedit ${LocalOutDir}/part-r-00000 & help: @echo "Usage:" @echo " make jar - Build Jar File." @echo " make clean - Clean up Output directory on HDFS." @echo " make run - Run your MapReduce code on Hadoop." @echo " make output - Download and show output file" @echo " make help - Show Makefile options." @echo " " @echo "Example:" @echo " make jar; make run; make output; make clean"
4.2.2 執行
- 執行Makefile,可以到該目錄下,執行make [參數],若不知道參數為何,可以打make 或 make help
- make 的用法說明
$ cd /home/waue/workspace/icas/ $ make Usage: make jar - Build Jar File. make clean - Clean up Output directory on HDFS. make run - Run your MapReduce code on Hadoop. make output - Download and show output file make help - Show Makefile options. Example: make jar; make run; make output; make clean
- 下面提供各種make 的參數
make jar
- 1. 編譯產生jar檔
$ make jar
make run
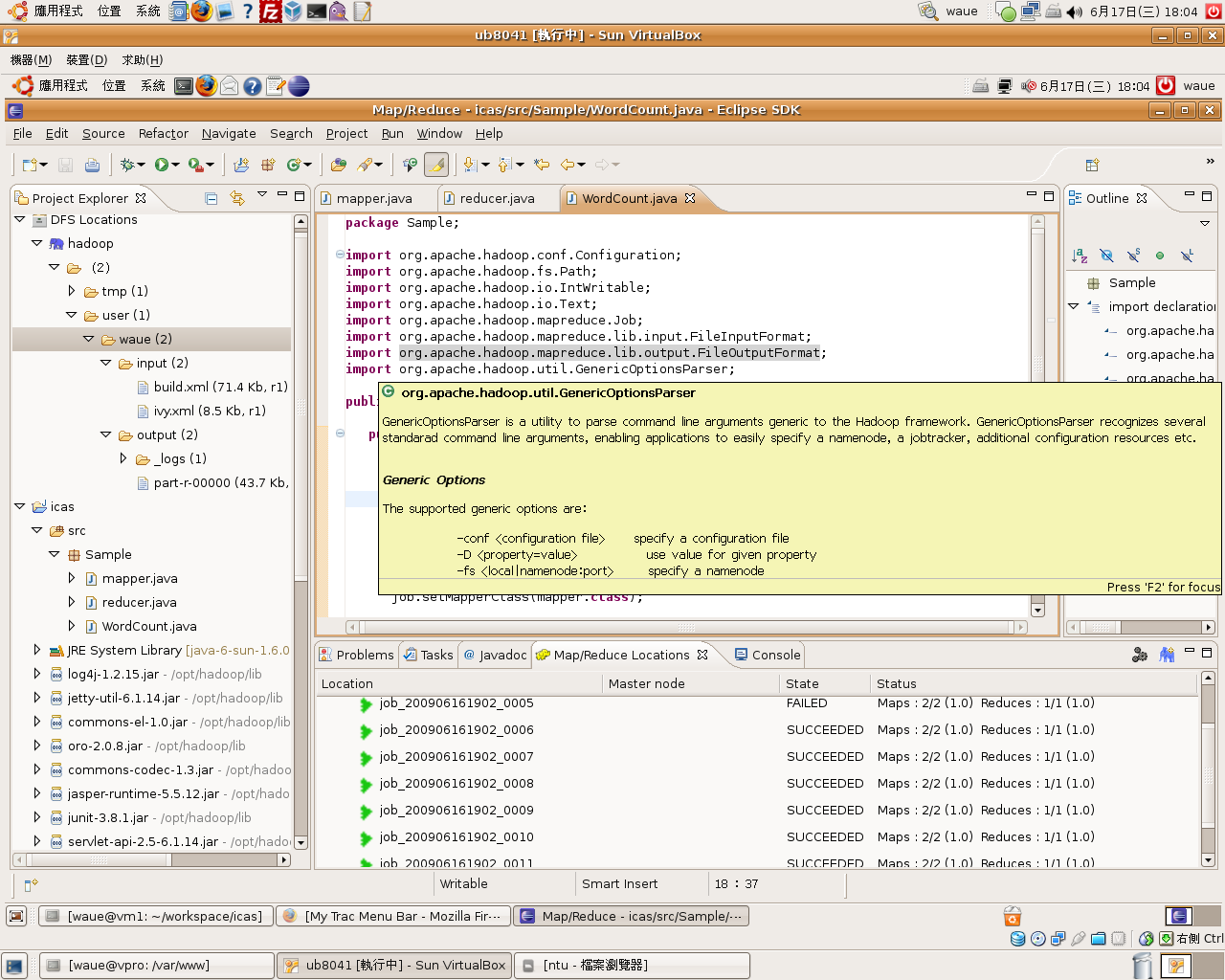
- 2. 跑我們的wordcount 於hadoop上
$ make run
- make run基本上能正確無誤的運作到結束,因此代表我們在eclipse編譯的程式可以順利在hadoop0.20的平台上運行。
- 而回到eclipse視窗,我們可以看到下方視窗run完的job會呈現出來;左方視窗也多出output資料夾,part-r-00000就是我們的結果檔

- 因為有設定完整的javadoc, 因此可以得到詳細的解說與輔助

make output
- 3. 這個指令是幫助使用者將結果檔從hdfs下載到local端,並且用gedit來開啟你的結果檔
$ make output
make clean
- 4. 這個指令用來把hdfs上的output資料夾清除。如果你還想要在跑一次make run,請先執行make clean,否則hadoop會告訴你,output資料夾已經存在,而拒絕工作喔!
$ make clean
五、結論
- 搭配eclipse ,我們可以更有效率的開發hadoop
- hadoop 0.20 與之前的版本api以及設定都有些改變,因此hadoop 環境的設定,需要看hadoop 0.20 的quickstart; 而如何使用 hadoop 0.20 的api,則可以看 /opt/hadoop/src/example/ 裡面的程式碼來提供初步的構想
Attachments (26)
- 1-1.png (41.7 KB) - added by waue 17 years ago.
- 2-1.png (28.7 KB) - added by waue 17 years ago.
- 2-2.png (48.6 KB) - added by waue 17 years ago.
- 2-3.png (64.8 KB) - added by waue 17 years ago.
- 2-4.png (42.0 KB) - added by waue 17 years ago.
- 2-4-2.png (52.6 KB) - added by waue 17 years ago.
- 2-5.png (85.1 KB) - added by waue 17 years ago.
- 2-5-1.png (122.6 KB) - added by waue 17 years ago.
- 2-5-2.png (85.0 KB) - added by waue 17 years ago.
- 2-5-3.png (56.4 KB) - added by waue 17 years ago.
- 2-6.png (56.4 KB) - added by waue 17 years ago.
- 2-6-1.png (52.8 KB) - added by waue 17 years ago.
- 2-6-2.png (53.4 KB) - added by waue 17 years ago.
- 3-1.png (40.7 KB) - added by waue 17 years ago.
- 3-2.png (173.1 KB) - added by waue 17 years ago.
- 3-3.png (40.4 KB) - added by waue 17 years ago.
- 3-4.png (52.5 KB) - added by waue 17 years ago.
- 3-5.png (212.1 KB) - added by waue 17 years ago.
- file-new-mapper.png (30.4 KB) - added by waue 17 years ago.
- file-new-mr-driver.png (30.2 KB) - added by waue 17 years ago.
- file-new-project.png (26.7 KB) - added by waue 17 years ago.
- file-new-reducer.png (25.8 KB) - added by waue 17 years ago.
- run-on-hadoop.png (398.2 KB) - added by waue 17 years ago.
- win-open-other.png (31.4 KB) - added by waue 17 years ago.
- 4-1.png (200.2 KB) - added by waue 17 years ago.
- 4-2.png (236.2 KB) - added by waue 17 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}