
| Version 3 (modified by adherelinux, 16 years ago) (diff) |
|---|
A partitioning based algothim to fuzzy co-cluster documents and words =
這篇文章主要是看完作者Wiliam-Chandra Thjhi,Lihui Chen 所寫下翻譯的
- introduction
在資料檢索中,文件的分類是個很重要的過程.他的應用包括新一代Web,目錄,查詢的擴展,視覺化的收尋.
儘管他是重要的但檢索文件尚未達到充分的發揮.有些問題仍然存在著,例如在練習過程的精確度,缺乏的分群解釋,
對於雜訊很敏感.而目前許多優越的計算以發展來對付這些問題.
處理低的精確度是由於高的維度,數個子空間的分群演算法,包括各種維度簡化的技術像是矩陣的分解,特徵分類或雙分群,
和項目的修剪的技術已在(F;orian et al.,2002)介紹過了.彈性的分類演算法已提出而穫得不確定的邊界條件.因此
改善去描述分類的解釋.一些重要的方法如fuzzy(Friedman et al,2004)和粗略集合(Lingras and West,2004;
Lingras er al,2004)的分類演算法,這兩篇論文而分類是分別表示為fuzzy集合與粗略的集合.特徵值選取技術已可以
去除資料的雜訊.有些進階文件的分群技術
Attachments (30)
-
cocluster公式.jpg
(16.6 KB) -
added by adherelinux 16 years ago.
cocluster公式
-
aggregation.jpg
(5.5 KB) -
added by adherelinux 16 years ago.
aggregation
-
uci.jpg
(1.8 KB) -
added by adherelinux 16 years ago.
uci
-
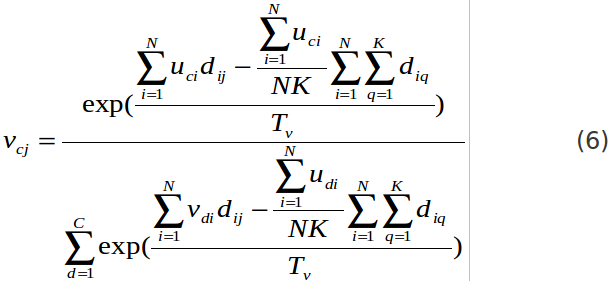
vcj.jpg
(1.9 KB) -
added by adherelinux 16 years ago.
vcj
-
lnu.jpg
(2.6 KB) -
added by adherelinux 16 years ago.
lnu
-
lnv.jpg
(2.5 KB) -
added by adherelinux 16 years ago.
lnv
-
du.jpg
(23.3 KB) -
added by adherelinux 16 years ago.
du
-
dv.jpg
(23.4 KB) -
added by adherelinux 16 years ago.
dv
-
djdu.jpg
(1.1 KB) -
added by adherelinux 16 years ago.
djdu
-
djdv.jpg
(1.1 KB) -
added by adherelinux 16 years ago.
djdv
-
J1.jpg
(4.6 KB) -
added by adherelinux 16 years ago.
J1
-
UV.jpg
(3.8 KB) -
added by adherelinux 16 years ago.
U V
-
W.jpg
(654 bytes) -
added by adherelinux 16 years ago.
W
-
Wmatrix.jpg
(2.3 KB) -
added by adherelinux 16 years ago.
Wmatrix
-
wij.jpg
(991 bytes) -
added by adherelinux 16 years ago.
wij
-
D.jpg
(2.1 KB) -
added by adherelinux 16 years ago.
D
-
sumuvd.jpg
(1.9 KB) -
added by adherelinux 16 years ago.
sumuvd
-
w.jpg
(389 bytes) -
added by adherelinux 16 years ago.
w
-
uT.jpg
(911 bytes) -
added by adherelinux 16 years ago.
UT
-
VT.jpg
(955 bytes) -
added by adherelinux 16 years ago.
VT
-
sumuv.jpg
(2.0 KB) -
added by adherelinux 16 years ago.
sumuv
-
|UT|.jpg
(1.1 KB) -
added by adherelinux 16 years ago.
|UT|
-
sumu=1.jpg
(846 bytes) -
added by adherelinux 16 years ago.
sumu
-
U<=1.jpg
(1.2 KB) -
added by adherelinux 16 years ago.
U<=1
-
v<=1.jpg
(608 bytes) -
added by adherelinux 16 years ago.
V<=1
-
cos.jpg
(543 bytes) -
added by adherelinux 16 years ago.
cos<=1
-
wij<=1.jpg
(1.3 KB) -
added by adherelinux 16 years ago.
wij<=1
-
dsum.jpg
(932 bytes) -
added by adherelinux 16 years ago.
dsum
-
w_ij.jpg
(372 bytes) -
added by adherelinux 16 years ago.
wij
-
J_1.jpg
(347 bytes) -
added by adherelinux 16 years ago.
J1
{kind=link}
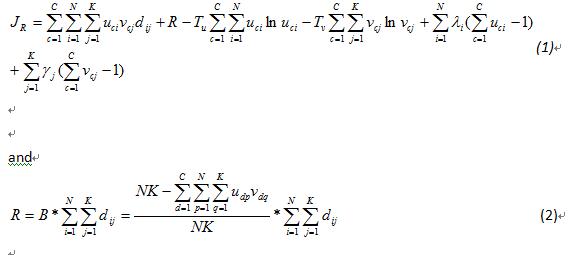{kind=link}
{kind=link}
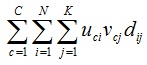{kind=link}
{kind=link}
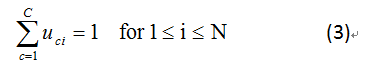{kind=link}
{kind=link}
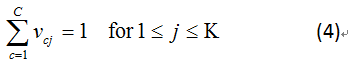{kind=link}
{kind=link}
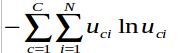{kind=link}
{kind=link}
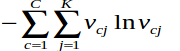{kind=link}
{kind=link}
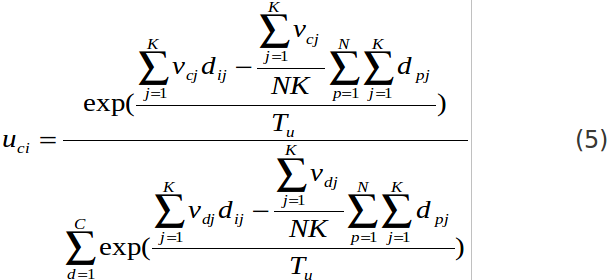{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
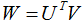{kind=link}
{kind=link}
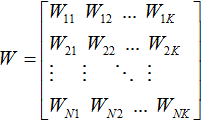{kind=link}
{kind=link}
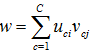{kind=link}
{kind=link}
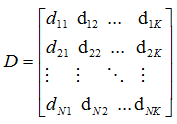{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
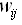{kind=link}
{kind=link}
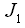{kind=link}
Download all attachments as: .zip