
實作五: Hadoop 叢集安裝
Lab5 : Hadoop Installation: Fully Distributed Mode
Lab5 : Hadoop Installation: Fully Distributed Mode
-
- 前言 Preface
- Step 0: 清除所有在實作一作過的環境
- Step 0: Erase installed Hadoop of Lab1
- Step 1: 設定兩台機器登入免密碼
- Step 1: Setup SSH key exchange
- Step 2: 安裝 Java
- Step 2: Install Java
- Step 3: 下載安裝 Hadoop 到"主機一"
- Step 3: Download Hadoop Source Package to Node 1
- Step 4: 設定 hadoop-env.sh
- Step 4: Configure hadoop-env.sh
- Step 5: 設定 *-site.xml
- Step 5: Configure *-site.xml
- Step 6: 設定 masters 及 slaves
- Step 6: Configure masters and slaves
- Step 7: HADOOP_HOME 內的資料複製到其他主機上
- Step 7: Copy entire HADOOP_HOME to other computers
- Step 8: 格式化 HDFS
- Step 8: Format HDFS
- Step 9: 啟動Hadoop
- Step 9: Start Hadoop
- Note: 停止 Hadoop
- Note: Stop Hadoop
前言 Preface
- 您手邊有兩台電腦,假設剛剛操作的電腦為"主機一" ,另一台則為"主機二" 。則稍後的環境如下
Now, You have two computer. Assume that you're in front of "node1" and the other computer is "node2"
管理Data的身份
for HDFS管理Job的身份
for MapReduce"主機一"
"node1"namenode + datanode jobtracker + tasktracker "主機二"
"node2"datanode tasktracker
- 這個實作會架設運作在叢集環境上的Hadoop,因此若是你的電腦還存在著之前的實作一的環境,請先作step 0,以移除掉之前的設定。
Following steps will go through the setup of cluster setup. If you kept the environment of Lab1, please erase that by instruction listed in Step 0.
- 確認您"主機一"的 hostname 與 "主機二" 的 hostname,並將下面指令有 主機一與主機二 的地方作正確的取代
Please replace "node1" and "node2" with the hostname of your computers.
- 維持好習慣,請幫你待會要操作的主機設 root 密碼
Since Ubuntu does not configure super user (root) password for you, please set your own super user (root) password.~$ sudo passwd
Step 0: 清除所有在實作一作過的環境
Step 0: Erase installed Hadoop of Lab1
- 在 "主機一" (有操作過 實作一 的電腦)上操作
On "node1", please remove the folder of /opt/hadoop and /var/hadoop created in Lab1node1:~$ cd ~ node1:~$ /opt/hadoop/bin/stop-all.sh node1:~$ rm -rf /var/hadoop node1:~$ sudo rm -rf /opt/hadoop node1:~$ rm -rf ~/.ssh
Step 1: 設定兩台機器登入免密碼
Step 1: Setup SSH key exchange
- 請注意我們實驗環境已經把 /etc/ssh/ssh_config裡的StrictHostKeyChecking改成no,下面的指令可以檢查,如果你的設定不同的話,請修改此檔會比較順。
Please check your /etc/ssh/ssh_config configurations. It should had been change the setting of "StrictHostKeyChecking?" to "no". If not, please modified it by editor.node1:~$ cat /etc/ssh/ssh_config |grep StrictHostKeyChecking StrictHostKeyChecking no
- 在"主機一" 上操作,並將 key 產生並複製到其他節點上
On "node1", generate SSH key and copy these keys to "node2".node1:~$ ssh-keygen -t rsa -f ~/.ssh/id_rsa -P "" node1:~$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys node1:~$ scp -r ~/.ssh 主機二(node2):~/
- 測試看看是否登入免密碼
To make sure that you've configure it correct, you could try following commands.node1:~$ ssh 主機二(node2) node2:~$ ssh 主機一(node1) node1:~$ exit node2:~$ exit node1:~$ ~$
Step 2: 安裝 Java
Step 2: Install Java
- 為兩台電腦安裝 Java
Install Java Runtime for both computer.node1:~$ sudo apt-get purge java-gcj-compat node1:~$ sudo apt-get install sun-java6-bin sun-java6-jdk sun-java6-jre node1:~$ ssh 主機二(node2) node2:~$ export LC_ALL=C node2:~$ sudo apt-get update node2:~$ sudo apt-get purge java-gcj-compat node2:~$ sudo apt-get install sun-java6-bin sun-java6-jdk sun-java6-jre node2:~$ exit node1:~$
Step 3: 下載安裝 Hadoop 到"主機一"
Step 3: Download Hadoop Source Package to Node 1
- 先在"主機一" 上安裝,其他node的安裝等設定好之後在一起作
We'll first install at node1, then copy the entire folder including settings to node2 later.
node1:~$ cd /opt node1:/opt$ sudo wget http://ftp.twaren.net/Unix/Web/apache/hadoop/core/hadoop-0.20.2/hadoop-0.20.2.tar.gz node1:/opt$ sudo tar zxvf hadoop-0.20.2.tar.gz node1:/opt$ sudo mv hadoop-0.20.2/ hadoop node1:/opt$ sudo chown -R hadooper:hadooper hadoop node1:/opt$ sudo mkdir /var/hadoop node1:/opt$ sudo chown -R hadooper:hadooper /var/hadoop
Step 4: 設定 hadoop-env.sh
Step 4: Configure hadoop-env.sh
- "主機一" 上用 gedit 編輯 conf/hadoop-env.sh
Use gedit to configure conf/hadoop-env.sh
/opt$ cd hadoop/ /opt/hadoop$ gedit conf/hadoop-env.sh
將以下資訊貼入 conf/hadoop-env.sh 檔內
Paste following information to conf/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-6-sun export HADOOP_HOME=/opt/hadoop export HADOOP_CONF_DIR=/opt/hadoop/conf export HADOOP_LOG_DIR=/tmp/hadoop/logs export HADOOP_PID_DIR=/tmp/hadoop/pids
- 注意,在此實作中,我們多設定了HADOOP_PID_DIR及HADOOP_LOG_DIR的參數,並且把值寫入到我們hadooper的家目錄中,此舉並非完全必要,但一個目的是介紹更多hadoop-env.sh內的參數,另一目的為讓log,pid等常變資料與hadoop家目錄分離
Note: in Lab5, we also configure two new variables HADOOP_PID_DIR and HADOOP_LOG_DIR. This is just to introduce that you can change the location to store logs and PIDs.
Step 5: 設定 *-site.xml
Step 5: Configure *-site.xml
- 接下來的設定檔共有3個 core-site.xml, hdfs-site.xml, mapred-site.xml,由於官方所提供的範例並無法直接執行,因此我們參考線上文件,做了以下的修改。
Next, let's configure three configuration files including core-site.xml, hdfs-site.xml, mapred-site.xml. Reference from "Hadoop Quick Start", please copy and paste the command:
/opt/hadoop# gedit conf/core-site.xml
將以下資料取代掉原本的內容
Then paste following settings in gedit.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://主機一(node1):9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/hadoop-${user.name}</value>
</property>
</configuration>
/opt/hadoop# gedit conf/hdfs-site.xml
將以下資料取代掉原本的內容
Then paste following settings in gedit.
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
/opt/hadoop# gedit conf/mapred-site.xml
將以下資料取代掉原本的內容
Then paste following settings in gedit.
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>主機一(node1):9001</value>
</property>
</configuration>
- 注意!fs.default.name = hdfs://主機一:9000/ ;而mapred.job.tracker = 主機一:9001,看出差異了嗎!一個有指hdfs://,一個沒有,重要!易混淆。[[BR]]Note: you will see that the parameter have little difference:
- fs.default.name = hdfs://node1:9000/
- mapred.job.tracker = node1:9001
Step 6: 設定 masters 及 slaves
Step 6: Configure masters and slaves
- 接著我們要編輯哪個主機當 namenode, 若有其他主機則為 datanodes
Next, we need to configure which node to be namenode and others to be datanodes.- 編輯 conf/slaves
edit conf/slaves/opt/hadoop$ gedit conf/slaves
- 編輯 conf/slaves
原本內容只有localhost一行,請刪除此行並換上"主機一" 及"主機二" 的ip
replace with IP address of "node1" and "node2"主機一 主機二
Step 7: HADOOP_HOME 內的資料複製到其他主機上
Step 7: Copy entire HADOOP_HOME to other computers
- 連線到"主機二" 作開資料夾/opt/hadoop及權限設定
SSH to node2 and create related folder for Hadoop and change permissions.hadooper@node1:/opt/hadoop$ ssh 主機二(node2) hadooper@node2:/opt/hadoop$ sudo mkdir /opt/hadoop hadooper@node2:/opt/hadoop$ sudo chown -R hadooper:hadooper /opt/hadoop hadooper@node2:/opt/hadoop$ sudo mkdir /var/hadoop hadooper@node2:/opt/hadoop$ sudo chown -R hadooper:hadooper /var/hadoop
- 複製"主機一" 的hadoop資料夾到"主機二" 上
hadooper@node2:/opt/hadoop$ scp -r node1:/opt/hadoop/* /opt/hadoop/ hadooper@node2:/opt/hadoop$ exit hadooper@node1:/opt/hadoop$
Step 8: 格式化 HDFS
Step 8: Format HDFS
- 以上我們已經安裝及設定好 Hadoop 的叢集環境,接著讓我們來啟動 Hadoop ,首先還是先格式化hdfs,在"主機一" 上操作
Now, we have configured the fully distributed mode of Hadoop Cluster. Before we start Hadoop related services, we need to format NameNode on node1.
hadooper@node1:/opt/hadoop$ bin/hadoop namenode -format
執行畫面如:
You should see results like this:
09/03/23 20:19:47 INFO dfs.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = 主機一 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.2 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/core/branches/branch-0.18 -r 736250; compiled by 'ndaley' on Thu Jan 22 23:12:08 UTC 2009 ************************************************************/ 09/03/23 20:19:47 INFO fs.FSNamesystem: fsOwner=hadooper,hadooper 09/03/23 20:19:47 INFO fs.FSNamesystem: supergroup=supergroup 09/03/23 20:19:47 INFO fs.FSNamesystem: isPermissionEnabled=true 09/03/23 20:19:47 INFO dfs.Storage: Image file of size 82 saved in 0 seconds. 09/03/23 20:19:47 INFO dfs.Storage: Storage directory /tmp/hadoop/hadoop-hadooper/dfs/name has been successfully formatted. 09/03/23 20:19:47 INFO dfs.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at 主機一 ************************************************************/
Step 9: 啟動Hadoop
Step 9: Start Hadoop
- bin/start-dfs.sh腳本會參照namenode上${HADOOP_CONF_DIR}/slaves文件的內容,在所有列出的slave上啟動datanode。
The bash script "bin/start-dfs.sh" will ssh to all computers listed in ${HADOOP_CONF_DIR}/slaves to start DataNodes?.
- 在"主機一" 上,執行下面的命令啟動HDFS:
On node1, you can use start-dfs.sh to start HDFS related services.
/opt/hadoop$ bin/start-dfs.sh
- http://主機一(node1):50070/ - Hadoop DFS 狀態
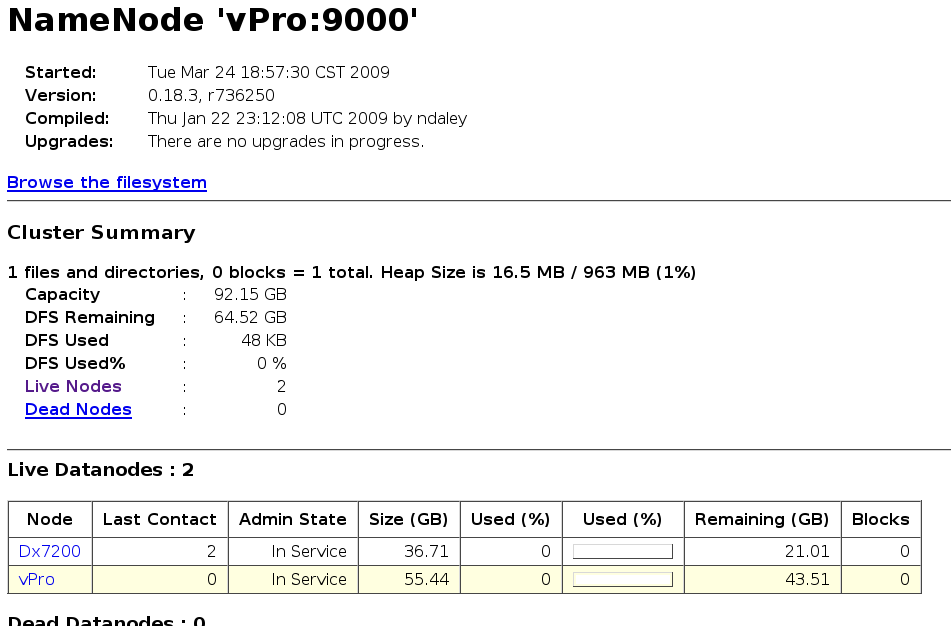

- ps: 然而JobTracker還沒啟動,因此 http://主機一:50030/ 網頁無法顯示
Since JobTracker is not yet running, you can't see http://node1:50030/
- bin/start-mapred.sh腳本會參照jobtracker上${HADOOP_CONF_DIR}/slaves文件的內容,在所有列出的slave上啟動tasktracker。
The bash script "bin/start-mapred.sh" will ssh to all computers listed in ${HADOOP_CONF_DIR}/slaves to start TaskTracker.
- 在"主機一"執行下面的命令啟動Map/Reduce:
You can use start-mapred.sh to start MapReduce related services.
/opt/hadoop$ /opt/hadoop/bin/start-mapred.sh
- 啟動之後, jobtracker也正常運作囉!
Now, you have JobTracker and TaskTracker running.
- http://主機一:50030/ - Hadoop 管理介面


Note: 停止 Hadoop
Note: Stop Hadoop
- 在"主機一" 上,執行下面的命令停止HDFS:
You can use stop-dfs.sh to stop HDFS related services./opt/hadoop$ bin/stop-dfs.sh
- 在"主機一" 上,執行下面的命令停止Map/Reduce:
You can use stop-mapred.sh to stop MapReduce related services./opt/hadoop$ bin/stop-mapred.sh
Last modified 16 years ago
Last modified on Aug 9, 2010, 3:37:18 PM