
Hypertable
【源起】
- 談到Hypertable要從Google用來儲存結構化數據的分散式資料庫,也就是Bigtable,開始說起,為了達到高讀取效能與Petabyte等級的資料庫容量,因此,Google設計出了一套底層為B-tree資料結構型式的儲存格式,並更改了傳統關聯式資料庫以Row來鎖定一筆資料的觀點,而採用更細緻化的Cell觀點來切入資料庫內容,並且在Cell又加上了版本控制的觀念以掌控日益新增的Cell資料版本數目,由於鎖定的目標由原本的Row縮小到Cell,因此用來定位之標的就由原本的Primary Key延伸而成為了Row Key+Column Family+Column Qualifier+Timestamp的組合,這些觀念會在稍後的章節詳細說明。然而,Bigtable的出現並不是為了取代傳統關聯式資料庫系統(RDBMS),像是在Google內部還是會用到像是MySQL等傳統資料庫,原因是這2種型態的資料庫訴求的功能面並不相同,Bigtable強調的是在數量龐大的資料庫中快速搜尋與讀取資料的效能,但是寫入效能不見得優於RDBMS,所以在一般Transaction導向應用的程式,如果常需要寫入動作或Rollback動作,而較不在乎Real-Time讀取效能的應用,還是以RDBMS較易於使用,關於Bigtable的應用面包括:存放網站索引記錄,Google Earth的衛星照片,Google Finance的金融資料記錄等等,可存放的資料單位容量大小從數kb到數十gb都可以存放,對於搜尋引擎公司來說Bigtable無疑是搜尋引擎之資料庫的最佳解決方案。
- 有鑑於此,搜尋引擎公司-Zvents-根據Google的9位研究人員在2006年發表的《Bigtable:Bigtable設計規格》為基礎,推出了一款以C++撰寫的分散式儲存結構化數據之資料庫系統-Hypertable開放原始碼專案。
【簡介】
- 總結來說Hypertable是一個高效能,分散式,開放源碼,與欄位導向的資料庫,可以儲存和處理叢集電腦上大量的節構化與非結構化的資料,它提供C++的API及HQL(Hypertable Query Language)給用戶端來存取資料庫內容。
- 它的用途並不是為了取代傳統的資料庫管理系統(像是MySQL與Oracle DB),而是為了可以儲存與管理大量的資料集。傳統的關連式資料庫RDBMs(Relational Database Management)是交易導向式,提供許多進階功能給使用者查詢結構化的資料庫內容。Hypertable為了逹到規模可彈性調整以及高效能的輸出,捨棄像是RDBMs常在使用的join或其他query的功能特色,MySQL之類的RDBMs系統屬於列導向較適合用於寫入動作較頻 繁的工作負載情形,Hypertable屬於欄位導向較適合讀取動作較頻繁的工作負載情形。
- 它建構於分散式檔案 系統(DFS)之上,目前有許多DFS系統,任一DFS均可架設Hypertable,一套DFS可以讓許多機器看起來就好像單一虛擬磁碟,而且都均有容錯與備份機制,因此DFSs可以結合許多叢集電腦的儲存資源,提供高速與大資料量的存取效能,故Hypertable架構在DFS之上也就可以提供高速與高容量的資料庫儲存空間。
【系統架構】

(reference:Architectural Overview)
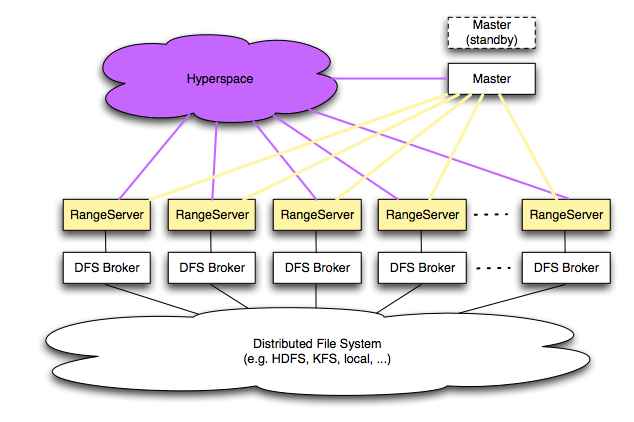
- Hyperspace
- 主要的作業內容為負責整個架構裡面的檔案系統鎖定管理服務,以及儲存檔案系統裡的Metadata資料,其鎖定方式分為獨佔式鎖定與分享式鎖定檔案或目錄,目前架構在同一時間只能運作一個Hyperspace實體,未來可能會實作出可以同時運作多個Hyperspace實體的分散式架構,此外,它儲存的Metadata資料可以幫助搜尋出分散式結構化數據的源頭,因此它也提供搜尋資料結構源頭置的服務。
- Range Server
- 資料表的資料內容會分開存放在不同的Row Ranges裡,一個Range Server負責掌管數個Row Ranges,一開始的資料表只會有一個Row Range,隨著資料內容增加,當一個Row Range超過預設的200MB限制大小時,會平分成2個Row Range,然後1個給原本的Range Server負責管理,另一個安排給其他由Master所指定的Range Server。
- Master
- DFS Broker
【欄位導向資料庫原理說明】
- Hypertable 將資料運用主鍵排列儲存在table裡。資料庫所有cell的值都是不解釋的字符數組串,沒有任何類型與型態。Hypertables藉由將tables切割成連續的範圍,並分佈儲存到不同的實體機器上,來擴大規模。Hypertable cluster有兩種server: (1) Range Servers - 掌管一個範圍內的一連串資料; (2) Master Servers - 處理管理工作和監督 Range Servers。單一實體機器可以同時跑 Range Server process 和 Master Server process。單一Range Server可以掌管許多不連續的ranges;單一 Master Server負責很聰明地將它們做分散的規劃管理。如果某單一range滿了的話,range則被分半並重新配置。上半部的range不變,下半部的range則被Master Server重新指定到一個新的Range Server。預設最大的range size是200MB。如果全部的 Range Servers都已滿了, Master Servers則會將ranges搬移到較少較不滿的Range Servers。ranges的清單及它們位在哪裡以METADATA型式存在table裡,如同正規的table一樣與Hypertable共存。而Hyperspace 提供一個類似一般正規檔案系統的命名空間,並為客戶端扮演一個鎖定管理者做控管。
- 以下是一個例子,顯示了存在Hypertable裡的資料是怎麼樣的,和該如何為非同質性的資料組儲存tags 和reviews。線上商店有許多商品項目,包括玩偶.傢俱和帽子。列識別符為玩偶.傢俱和帽子的名字,並且有許多行用來描述其每個tag 和review。前四行指示這個tag的行家族之資料點是tag,行識別符是標籤的名稱,值是我們想給其加上什麼標籤值。第五第六行家族指示它是個review,識別符是書寫者的名稱,其內容值才是真正的review。
| key | tag:striped | tag:fourlegs | tag:velvet | tag:male | tag:comfortable | review:joey | review:susan | price:US | price:EU |
| Zebra | 803 | 212 | 0 | 6 | 9 | "I like my zebra" | 25.00 | 20.00 | |
| Ottoman | 1 | 343 | 298 | 0 | 0 | "" | "this is an excellent ottoman" | 200.00 | 175.00 |
| Fedora | 3 | 0 | 145 | 34 | 78 | "" | "a very fine hat" | 50.00 | 40.00 |
- Hypertable 裡的schemas 非常有彈性, 只有行家族需要事先被定義。建立table的HQL命令如下﹔
CREATE TABLE Items {
tag, review, price
};
- 資料以 key:value組的方式儲存。所有資料的修定版都儲存在Hypertable裡,所以時間戳記是keys裡相當重要的一個部分。每單一資料點的典型key是<row><column-family><column-qualifier><timestamp>。所挑選到的時間戳記通常會以一個range做傳入,然後回傳一整個range的所有值。這可以使得很容易看出資料的舊版本值和看其隨著時間的變化,並且可以確保之前的資料都有被儲存起來而不是被覆寫過去。這預設的行為可以被覆寫而儲存成一個固定號碼的最近版本,並允許較舊的版本做鬆散的垃圾收集。以下為Zebra列的時間戳記版本:
| time | key | tag:striped | tag:fourlegs | tag:velvet | tag:male | tag:comfortable | review:joey | review:susan | price:US | price:EU |
| t=1 | Zebra | 803 | 212 | 0 | 6 | 9 | "I like my zebra" | 25.00 | 20.00 | |
| t=2 | Zebra | 804 | ||||||||
| t=3 | Zebra | 216 | 1 | "I REALLY like my zebra" | ||||||
| t=4 | Zebra | 24.99 | 19.99 | |||||||
- 所以在t=4,Zebra列就會有以下這樣的值:
| t=4 | Zebra | 804 | 216 | 1 | 6 | 9 | "I REALLY like my zebra" | 24.99 | 19.99 |
- Hypertable透過使用Cell Caches 和 Cell Stores 可以有效率的處理隨機更新。一個range實際上由許多Cell Stores組成。在一個cell store裡的所有列都是以列識別符做排序。Hypertable當一個寫入的動作發生,此資訊會先被寫入DFS的commit log,然後再存入Cell Cache的記憶體。 當Cell Cache達到大小限制,就會被壓縮並寫到硬碟裡成為Cell Store。Cell stores終究是不連續的,所以Heap Merge scanner負責聚集在cell cache 和cell store裡的key/value pairs,並且回傳排過序後的值。當range達到一個cell store的限制, Heap Merge就會啟動並且壓縮多個cell stores 成一個。不過在理想的狀況下,每個range最好只擁有單一的Cell Store。
- Hypertable 提供使用者可以透過存取群組機制來控制行資料如何實際地儲存在DFS裡。每一行家族屬於單一存取群組,所有再存取群組裡行家族的資料都實際地一起儲存在硬碟裡。這可以改善被存取頻繁的行家族之讀寫效能。以下舉個例子,一個table有100個行家族,但只有兩個行家族比較常被存取。如果這兩個行家族一起被儲存在他們自己的存取群組,那麼為了要存取它們,系統將作disk I/O只須針對這兩行。若沒有存取群組,即使只有兩行的資料要存取,這100行的資料都將實際地被讀寫。
【效能】
- Performance Test: AOL Query Log(from Google)
- Machine Profile
- 8 data nodes
- each node
- 1 x 1.8GHz Dual-core Opteron Processor 2210
- 4 GB RAM
- 4 x 7200 RPM SATA drives (mounted JBOD)
- each node
- 8 data nodes
- The AOL query logs were inserted into an 8-node Hypertable cluster. The average size of each row key was ~7 bytes and each value was ~15 bytes. The insert rate (with 4 simultaneous insert processes) was approximately 410K inserts/s. The table was scanned at a rate of approximately 671K cells/s.
- Machine Profile
【實務應用】
【同質專案】
- HBase: Bigtable-like structured storage for Hadoop HDFS
- Hypertable is based very closely on the design of Bigtable, with a few modifications. Hypertable is designed for speed and is written in C++, while Hbase is in Java.
- Thrudb
- Thrudb is a set of simple services built on top of Facebook’s Thrift framework that provides indexing and document storage services for building and scaling websites. Its purpose is to offer web developers flexible, fast and easy-to-use services that can enhance or replace traditional data storage and access layers.
- DistStore
- DistStore? is a family of lightweight Thrift based web services which are extremely scalable in both throughput and dataset size. Its purpose is to offer a simple and flexible data storage solution that can grow with your project from inception to millions of users.
【參考】
- HyperTable 官方網站
- 翻譯:Google BigTable - 原文(PDF)
- Introducing Hypertable - a new open source database project
- 開放原始碼專案 Hypertable(BigTable clone)的效率
- LinuxWorld Hypertable 專訪 Doug Judd (PodCast) - 包含如何使用 HyperTable 來匯入大量 Apache Log 的範例
- hypertable 在 Google Code 的討論群
- How Hypertable Works - Google Code 上的說明文件
- Google Code 上的範例 Apache log load example
- Cloud Computing 雲端運算
- A Hypertabular Visualizer of Query Results
- Hypertable的架構說明
【相關新聞】
【技術文章】
- Hypertable Installation Guide: How to install
- Hypertable Documentation Tree: Source Code Documentation Tree(Doxygen)
- Hypertable Query Language(HQL) Guide: HQL Hwo To
【網路上的討論新聞】
- 關聯式資料庫的優勢逐漸消失??
- 關聯式資料庫管理系統成長動能大增

【常見問題】
- Hypertable資料庫系統在執行關閉伺服器指令後,再重新啟動時裡面的資料表都會遺失?
Ans: 在Hypertable裡所有的系統設定都包含在conf目錄下的hypertable.cfg檔案裡,裡面有一個DfsBroker.Local.Root設定值可以指定要使用的檔案系統路徑,預設的系統路徑是Hypertable工作目錄的fs/local路徑裡,以fs/local目錄建立在本機磁碟機為例,啟動後所建立的表格都會登錄在fs/local/hypertable/tables目錄裡,一旦停止服務後這些資料表資料又會遺失,因此上網路討論區找到了一些資料來佐證目前alpha版的hypertable是不支援永續儲存資料庫功能。討論區原文如下:問題: what is the clean way to shut down a local instance of Hypertable? If I just use bin/kill-servers.sh (which as far as I see just sends a SIGKILL which does not look like a good way to shut down a database), I do not see any tables next time I start servers with bin/start-all-servers.sh local. Hypertable的作者Doug回覆: As far as clean shutdown goes, there currently isn't one. This is why we released the software as "alpha". We're currently working on recovery and as soon as it's in place, we'll move from "alpha" to "beta".
輔充說明:HBase支援永續儲存資料庫功能
【研究團隊】
- 此網頁內容為國網中心雲端技術研究小組之雲端資料庫(Cloud DB)研究人員之共同研究心得分享,內容如有疏誤請多包含。
- 技術顧問: 王耀聰
- 編輯與研究人員: 陳惠珊,王心怡
Last modified 18 years ago
Last modified on Jul 26, 2008, 12:50:41 AM
Attachments (1)
- SystemOverview.jpg (162.2 KB) - added by sunny 18 years ago.
{kind=link}
Download all attachments as: .zip