
實作三: Hadoop 叢集安裝
前言
- 您手邊有兩台電腦,假設剛剛操作的電腦為Node 1 ,另一台則為Node 2 。則稍後的環境如下
管理Data的身份 管理Job的身份 Node 1 namenode(master)& datanode tasktracker(slave) Node 2 jobtracker(master)& datanode(slave) tasktracker
- 這個實做會架設運作在叢集環境上的Hadoop,因此若是你的電腦還存在著之前的實做一的環境,請先作step 0,以移除掉之前的設定。
- 以下node01代表你Node 1 的ip位址,node02為你Node 2 的ip位址,請查清楚之後作設定
- 確認您Node 1的 hostname 與 Node 2 的 hostname,並將下面指令有 node01與node02 的地方作正確的取代
- 為了簡化操作步驟,大部分的指令在Node 1 執行即可,不過step2 的安裝java則需要在Node 2 上實機操作喔!
- 維持好習慣,請幫你待會要操作的主機設root密碼
~$ sudo passwd
清除所有在實做一作過的環境
- 在 Node 1 (有操作過 實做一 的電腦)上操作
~$ cd ~ ~$ killall java ~$ rm -rf /tmp/hadoop-hadooper* ~$ sudo rm -rf /opt/hadoop ~$ rm -rf ~/.ssh
step 0. 設定機器的ip & hostname 資訊
- 確認您Node 1的 hostname 與 Node 2 的 hostname,並將下面指令有 node01與node02 的地方作正確的取代
step 1. 設定兩台機器登入免密碼
- 在Node 1 上操作
~$ sudo gedit /etc/ssh/ssh_config
- 把原本的ask改成no
StrictHostKeyChecking no
- 並且把此檔替換到其他node
~$ sudo su - ~# scp /etc/ssh/ssh_config node2:/etc/ssh/ ~# exit
- 接著將key複製到其他node上
~$ ssh-keygen -t rsa -f ~/.ssh/id_rsa -P "" ~$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys ~$ scp -r ~/.ssh node02:~/
- 測試看看是否登入免密碼
~$ ssh node02 ~$ ssh node01 ~$ exit ~$ exit ~$
- 完成後請登入確認不用輸入密碼,(第一次登入需按 yes ,第二次就可以直接登入到系統),以免日後輸入密碼不隻手軟而已....
step 2. 安裝java
- 為兩台電腦安裝java
- Node 1 & Node 2 都要操作以下指令
~$ sudo apt-get purge java-gcj-compat ~$ sudo apt-get install sun-java6-bin sun-java6-jdk sun-java6-jre ~$ ssh node2 ~$ sudo apt-get purge java-gcj-compat ~$ sudo apt-get install sun-java6-bin sun-java6-jdk sun-java6-jre ~$ exit
- Node 1 & Node 2 都要操作以下指令
step 3. 下載安裝Hadoop到Node 1
- 先在Node 1 上安裝,其他node的安裝等設定好之後在一起作
~$ cd /opt /opt$ sudo wget http://ftp.twaren.net/Unix/Web/apache/hadoop/core/hadoop-0.18.3/hadoop-0.18.3.tar.gz /opt$ sudo tar zxvf hadoop-0.18.3.tar.gz /opt$ sudo mv hadoop-0.18.3/ hadoop /opt$ sudo chown -R hadooper:hadooper hadoop
step 4. 設定 hadoop-env.sh
- Node 1 上用gedit 編輯 conf/hadoop-env.sh
/opt$ cd hadoop/ /opt/hadoop$ gedit conf/hadoop-env.sh
將以下資訊貼入 conf/hadoop-env.sh 檔內
export JAVA_HOME=/usr/lib/jvm/java-6-sun export HADOOP_HOME=/opt/hadoop export HADOOP_CONF_DIR=/opt/hadoop/conf export HADOOP_LOG_DIR=/tmp/hadoop/logs export HADOOP_PID_DIR=/tmp/hadoop/pids
- 注意,在此實做中,我們多設定了HADOOP_PID_DIR及HADOOP_LOG_DIR的參數,並且把值寫入到我們hadooper的家目錄中,此舉並非完全必要,但一個目的是介紹更多hadoop-env.sh內的參數,另一目的為讓log,pid等常變資料與hadoop家目錄分離
step 5. 設定 hadoop-site.xml
- 第二個設定檔是 hadoop-site.xml,由於官方所提供的範例並無法直接執行,因此我們參考線上文件,做了以下的修改。
/opt/hadoop# gedit conf/hadoop-site.xml
將以下資料取代掉原本的內容
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node01:9000/</value>
<description> </description>
</property>
<property>
<name>mapred.job.tracker</name>
<value>node01:9001</value>
<description> </description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop/hadoop-${user.name}</value>
<description> </description>
</property>
</configuration>
- 注意! 我們多加了一個參數hadoop.tmp.dir,讓預設的中介資料存放在/tmp/hadoop/ 而不是/tmp/ 下,更多內容可以看conf/hadoop-default.xml
- 注意!fs.default.name = hdfs://node01:9000/ ;而mapred.job.tracker = node01:9001,看出差異了嗎!一個有指hdfs://,一個沒有,重要!易混淆。
step 6. 設定masters及slaves
- 接著我們要編輯哪個主機當namenode, 若有其他主機則為datanodes
- 編輯 conf/slaves
/opt/hadoop$ gedit conf/slaves
- 編輯 conf/slaves
原本內容只有localhost一行,請刪除此行並換上Node 1 及Node 2 的ip
node01 node02
step 7. Hadoop_Home內的資料複製到其他主機上
- 在Node 1 上對遠端Node 2 作開資料夾/opt/hadoop及權限設定
/opt/hadoop$ ssh node02 "sudo mkdir /opt/hadoop" /opt/hadoop$ ssh node02 "sudo chown -R hadooper:hadooper /opt/hadoop"
- 複製Node 1 的hadoop資料夾到Node 2 上
/opt/hadoop$ scp -r /opt/hadoop/* node02:/opt/hadoop/
step 8. 格式化HDFS
- 以上我們已經安裝及設定好 Hadoop 的叢集環境,接著讓我們來啟動 Hadoop ,首先還是先格式化hdfs,在Node 1 上操作
/opt/hadoop$ bin/hadoop namenode -format
執行畫面如:
09/03/23 20:19:47 INFO dfs.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = node01 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.18.3 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/core/branches/branch-0.18 -r 736250; compiled by 'ndaley' on Thu Jan 22 23:12:08 UTC 2009 ************************************************************/ 09/03/23 20:19:47 INFO fs.FSNamesystem: fsOwner=hadooper,hadooper 09/03/23 20:19:47 INFO fs.FSNamesystem: supergroup=supergroup 09/03/23 20:19:47 INFO fs.FSNamesystem: isPermissionEnabled=true 09/03/23 20:19:47 INFO dfs.Storage: Image file of size 82 saved in 0 seconds. 09/03/23 20:19:47 INFO dfs.Storage: Storage directory /tmp/hadoop/hadoop-hadooper/dfs/name has been successfully formatted. 09/03/23 20:19:47 INFO dfs.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at node01 ************************************************************/
step 9. 啟動Hadoop
- bin/start-dfs.sh腳本會參照namenode上${HADOOP_CONF_DIR}/slaves文件的內容,在所有列出的slave上啟動datanode。
- 在Node 1 上,執行下面的命令啟動HDFS:
/opt/hadoop$ bin/start-dfs.sh
- http://node01:50070/ - Hadoop DFS 狀態
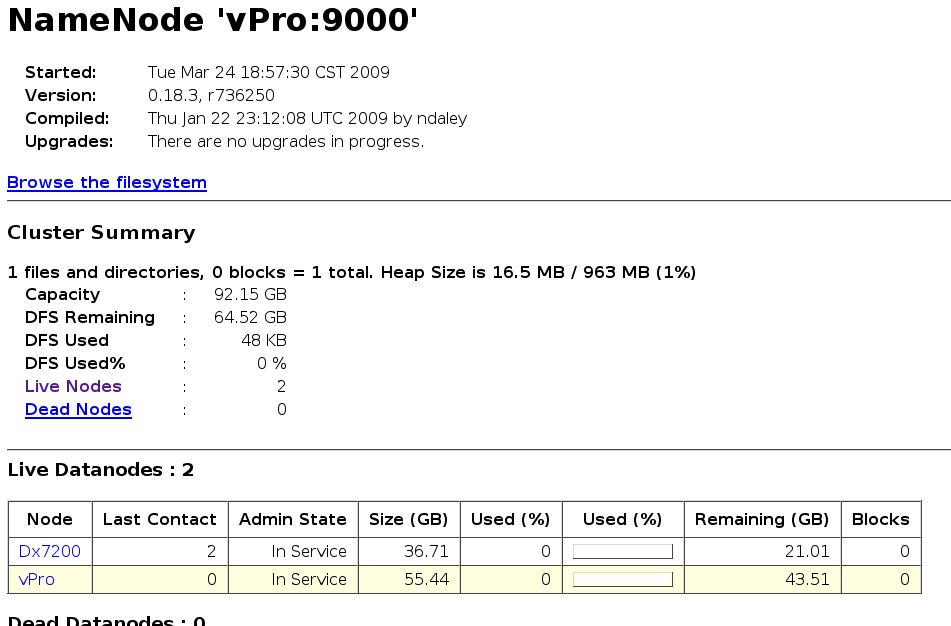

- ps: 然而JobTracker還沒啟動,因此 http://node01:50030/ 網頁無法顯示
- bin/start-mapred.sh腳本會參照jobtracker上${HADOOP_CONF_DIR}/slaves文件的內容,在所有列出的slave上啟動tasktracker。
- 用ssh 操作Node 2 執行下面的命令啟動Map/Reduce:
/opt/hadoop$ /opt/hadoop/bin/start-mapred.sh
- 啟動之後, jobtracker也正常運作囉!
- http://node01:50030/ - Hadoop 管理介面


step 10. 停止hadoop
- 在Node 1 上,執行下面的命令停止HDFS:
/opt/hadoop$ bin/stop-dfs.sh
- bin/stop-dfs.sh腳本會參照namenode上${HADOOP_CONF_DIR}/slaves文件的內容,在所有列出的slave上停止namenode
- 在Node 1 上,執行下面的命令停止Map/Reduce:
/opt/hadoop$ bin/stop-mapred.sh
- bin/stop-mapred.sh腳本會參照jobtracker上${HADOOP_CONF_DIR}/slaves文件的內容,在所有列出的slave上停止tasktracker。
練習
- 看 conf/hadoop-default.xml 的更多內容
- 和別人組隊,組成4台node的cluster,其中Node 1 只當 namenode ,Node 2 只當 jobtracker,而node3, node4 兩台電腦則身兼 datanode及tasktracker的工作。
Last modified 17 years ago
Last modified on Apr 9, 2009, 4:14:05 PM
Attachments (2)
- datanode.png (58.5 KB) - added by waue 17 years ago.
- job.png (47.6 KB) - added by waue 17 years ago.
Download all attachments as: .zip