
| Version 3 (modified by wade, 18 years ago) (diff) |
|---|
Introduction
MPI ( Message Passing Interface) ,一個用於平行計算的平臺。
MPICH Documents
MPI Documents
LLNL參考資料
Classifying of parallel computers
- SISD(Single-Instruction Single-Data)
如普通的單核心 PC ,只有單一指令與資料,ex: a = 1 + 1。
- SIMD(Single-Instruction Multiple-Data)
同一組指令,多組資料,ex: a = b + 1, b 是一組陣列,則同一時間就可以計算完成。而不需要算完 b[1] + 1,再算 b[1] + 1…再算 b[n] + 1。
- MISD(ultiple-Instruction Single-Data)
多組指令,單一組資料,ex: a = (2 + 3) + (2 - 3) + (2 * 3) + (2 / 3),則四臺機器各執行 2 跟 3 的操作指令 「=」、「-」、「*」及「/」中的一種,用的資料是 2 跟 3。
- MIMD(Multiple-Instruction Multiple-Data)
多組指令,多組資料,ex: a = (b + c) + (d - e) + (f * g),如果有三臺機器可分別執行(b + c) 、 (d - e) 及 (f * g),則三個運算可同時進行。
Design
指令及資料量切割的越小越有助於平行運算,但切割過小將會使傳輸次數及傳輸量增大,而且每次傳輸所需要的時間遠大於每次的計算,因此在設計程式為了得最高效能,須考慮到計算量、計算進度、傳輸量及傳輸速度。
Communication
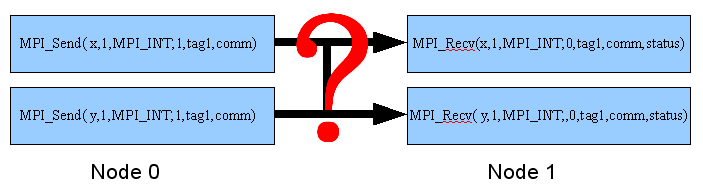
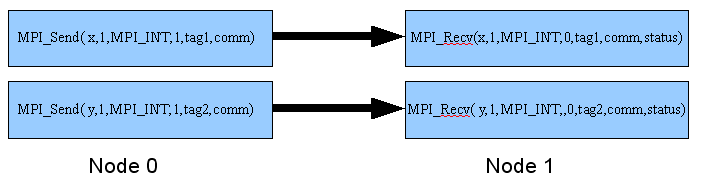
- Point to point communication 主要用在 one to one ,特定指定機器與機器間的傳送,傳送與接收的次數要相同,同一筆資料可以分多次傳送,但是每次傳送皆需花費時間,要考慮網路速度及機器處理能力。


- Collective communication
- MPI_Scatter、MPI_Gather、MPI_Allgather、MPI_Reduce、MPI_Allreduce、 MPI_Barrier
API
Constants
MPI_Wtime
取得系統時間:
MPI_Init(); MPI_Comm_size (MPI_COMM_WORLD, &nproc); MPI_Comm_rank (MPI_COMM_WORLD, &myid); MPI_Barrier (MPI_COMM_WORLD); time1=MPI_Wtime() . . . time2=MPI_Wtime() – time1; printf (“myid, clock time= %f\t%f\n”, myid,time2); MPI_Finalize(); Return 0;
DEMO_1
#include <stdio.h>
#include <mpi.h>
int nproc, myid;
main (argc, argv)
int argc;
char **argv;
{
MPI_Init(&argc, &argv);
MPI_Comm_size (MPI_COMM_WORLD, &nproc);
MPI_Comm_rank (MPI_COMM_WORLD, &myid);
………
MPI_Finalize();
return 0;
#include <mpi.h> mpich 的 head file。
nproc 此次運算中,參與的 cpu 的總數。
myid 此次運算中,目前本身是第幾顆 cpu。
MPI_Init(&argc, &argv) 初始化使用 mpi 的環境。
MPI_Comm_size(MPI_COMM_WORLD, &nproc) 回傳此次運算中,參與的 cpu 總數。
MPI_Comm_rank (MPI_COMM_WORLD, &myid) 回傳目前自己是第幾個 cpu。
MPI_Finalize() 結束平行運算
Bench mark
Attachments (3)
- mpi-fig-1.png (5.0 KB) - added by wade 18 years ago.
- mpi-fig-2.png (3.4 KB) - added by wade 18 years ago.
- MPICH-1.3.ppt (537.5 KB) - added by wade 18 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip