
| Version 18 (modified by chris, 18 years ago) (diff) |
|---|
- The sample R program is from here
- Original R Program (without Rmpi)
start_time <- Sys.time() # first make some data n <- 1000 # number of obs p <- 30 # number of variables x <- matrix(rnorm(n*p),n,p) beta <- c(rnorm(p/2,0,5),rnorm(p/2,0,.25)) y <- x %*% beta + rnorm(n,0,20) thedata <- data.frame(y=y,x=x) # summary(lm(y~x)) fold <- rep(1:10,length=n) fold <- sample(fold) rssresult <- matrix(0,p,10) for (j in 1:10) { for (i in 1:p) { templm <- lm(y~.,data=thedata[fold!=j,1:(i+1)]) yhat <- predict(templm,newdata=thedata[fold==j,1:(i+1)]) rssresult[i,j] <- sum((yhat-y[fold==j])^2) } } end_time <- Sys.time() runTime<-difftime(end_time,start_time,units="secs") write(runTime,file="single_10_runTime",append=TRUE) write(rssresult,file="single_10_result") q(save="no") - Parallelized R Program (with Rmpi)
# Create Start Timer start_time<-Sys.time() # Initialize MPI library("Rmpi") # Notice we just say "give us all the slaves you've got." mpi.spawn.Rslaves(nslaves=2) if (mpi.comm.size() < 2) { print("More slave processes are required.") mpi.quit() } .Last <- function(){ if (is.loaded("mpi_initialize")){ if (mpi.comm.size(1) > 0){ print("Please use mpi.close.Rslaves() to close slaves.") mpi.close.Rslaves() } print("Please use mpi.quit() to quit R") .Call("mpi_finalize") } } # Function the slaves will call to perform a validation on the # fold equal to their slave number. # Assumes: thedata,fold,foldNumber,p foldslave <- function() { # Note the use of the tag for sent messages: # 1=ready_for_task, 2=done_task, 3=exiting # Note the use of the tag for received messages: # 1=task, 2=done_tasks junk <- 0 done <- 0 while (done != 1) { # Signal being ready to receive a new task mpi.send.Robj(junk,0,1) # Receive a task task <- mpi.recv.Robj(mpi.any.source(),mpi.any.tag()) task_info <- mpi.get.sourcetag() tag <- task_info[2] if (tag == 1) { foldNumber <- task$foldNumber rss <- double(p) for (i in 1:p) { # produce a linear model on the first i variables on # training data templm <- lm(y~.,data=thedata[fold!=foldNumber,1:(i+1)]) # produce predicted data from test data yhat <- predict(templm,newdata=thedata[fold==foldNumber,1:(i+1)]) # get rss of yhat-y localrssresult <- sum((yhat-thedata[fold==foldNumber,1])^2) rss[i] <- localrssresult } # Send a results message back to the master results <- list(result=rss,foldNumber=foldNumber) mpi.send.Robj(results,0,2) } else if (tag == 2) { done <- 1 } # We'll just ignore any unknown messages } mpi.send.Robj(junk,0,3) } # We're in the parent. # first make some data n <- 1000 # number of obs p <- 30 # number of variables # Create data as a set of n samples of p independent variables, # make a "random" beta with higher weights in the front. # Generate y's as y = beta*x + random x <- matrix(rnorm(n*p),n,p) beta <- c(rnorm(p/2,0,5),rnorm(p/2,0,.25)) y <- x %*% beta + rnorm(n,0,20) thedata <- data.frame(y=y,x=x) fold <- rep(1:10,length=n) fold <- sample(fold) #summary(lm(y~x)) # Now, send the data to the slaves mpi.bcast.Robj2slave(thedata) mpi.bcast.Robj2slave(fold) mpi.bcast.Robj2slave(p) # Send the function to the slaves mpi.bcast.Robj2slave(foldslave) # Call the function in all the slaves to get them ready to # undertake tasks mpi.bcast.cmd(foldslave()) # Create task list tasks <- vector('list') for (i in 1:10) { tasks[[i]] <- list(foldNumber=i) } # Create data structure to store the results rssresult = matrix(0,p,10) junk <- 0 closed_slaves <- 0 n_slaves <- mpi.comm.size()-1 while (closed_slaves < n_slaves) { # Receive a message from a slave message <- mpi.recv.Robj(mpi.any.source(),mpi.any.tag()) message_info <- mpi.get.sourcetag() slave_id <- message_info[1] tag <- message_info[2] if (tag == 1) { # slave is ready for a task. Give it the next task, or tell it tasks # are done if there are none. if (length(tasks) > 0) { # Send a task, and then remove it from the task list mpi.send.Robj(tasks[[1]], slave_id, 1); tasks[[1]] <- NULL } else { mpi.send.Robj(junk, slave_id, 2) } } else if (tag == 2) { # The message contains results. Do something with the results. # Store them in the data structure foldNumber <- message$foldNumber rssresult[,foldNumber] <- message$result } else if (tag == 3) { # A slave has closed down. closed_slaves <- closed_slaves + 1 } } # plot the results # plot(apply(rssresult,1,mean)) end_time<-Sys.time() runTime<-difftime(end_time,start_time,units="secs") write(runTime, file="parallel_10_runTime",append=TRUE) write(rssresult, file="parallel_10_result") mpi.close.Rslaves() mpi.quit(save="no")
- Original R Program (without Rmpi)
- We could find that there are double loops in the sample program, one is j, and the other is p.
To control one of the variables at one time(either j or p) is the way to know how much does the performance have been improved when Rmpi applying.
In the meanwhile, we compare how much does the performance improve when the number of slaves are 3 and 6.
- The running times(secs) for variable j of sample program (p is 30) are as below:
j(times of loop) single paralle with 3 slaves parallel with 6 slaves 10 7.319691 3.738059 2.707863 50 33.96304 11.76658 6.84227 100 71.7085 22.68779 11.85747 150 111.417 32.51246 16.98184 200 142.6771 42.51736 22.92909 250 176.2949 53.08824 27.35953
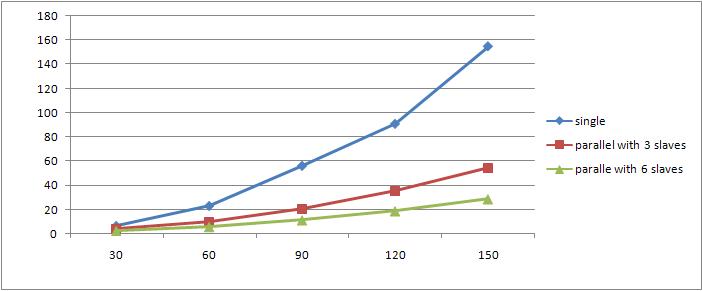
- The running times(secs) for variable p of sample program (j is 10) are as below:
p(times of loop) single paralle with 3 slaves parallel with 6 slaves 30 6.462582 3.91415 2.550209 60 22.9513 9.87096 5.806265 90 56.07782 20.56819 11.25752 120 90.7383 35.26347 18.84071 150 154.7837 54.48117 28.72215
- The Curve is as below:
The Y-aix represents runtime of both single mode and parallel mode.(units: seconds)
The X-aix represents how many times of loop set by us in the sample program
For variable j :

For variable p :

- We could proof that Rmpi will let the sample program to run faster and faster when times of loop larer and larer.
Attachments (3)
- Rmpi_example_test_result.jpg (17.6 KB) - added by chris 18 years ago.
- for_j_loop_times.JPG (26.0 KB) - added by chris 18 years ago.
- for_p_loop_times.JPG (24.5 KB) - added by chris 18 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip