
| Version 9 (modified by waue, 16 years ago) (diff) |
|---|
讓 Nutch 支援中文分詞 方法教學
Nutch 1.0 + IK-Analyzer 3.1.6 中文分詞庫
前言
- Nutch 1.0 + IK-Analyzer 3.1.6 中文分詞庫 的詳細方法
- 本篇參考 nutch-1.0中文分词(原文連結),並且修正與補充
- nutch 1.0 的下載位置
$nutch-1.0/ 你下載nutch-1.0 並解壓縮的資料夾目錄位址,也是用來重編nutch的資料夾 如:/home/user/nutch-1.0/ $my_nutch_dir 原有的nutch資料夾,接著會被擴充ika中文詞庫 /opt/nutchez/nutch/ $my_tomcat_dir 原本被用來放nutch網頁(在tomcat內)的資料夾 /opt/nutchez/tomcat
何謂中文分詞
中文自動分詞指的是使用計算機自動對中文文本進行詞語的切分,即像英文那樣使得中文句子中的詞之間有空格以標識。中文自動分詞被認為是中文自然語言處理中的一個最基本的環節。
簡單來說,以"今天天氣真好"這段字而言,若搜尋"氣真"
- 沒有中文分詞的結果為:1筆 => 今天天氣真好
- 有中文分詞:0筆 (因為詞庫為今天、天天、天氣、真、真好、好)
下面的例子即為,透過完成括充中文分詞(ik-analyzer)之後的nutch搜尋引擎,對"國家高速網路中心"的首頁(http://www.nchc.org.tw/tw/) 作資料爬取,並以此為搜尋資料庫。
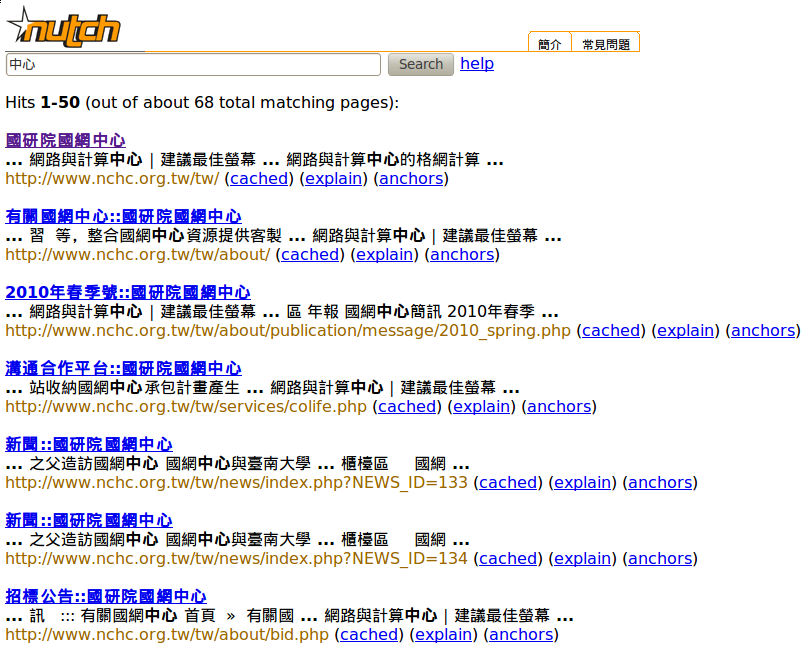
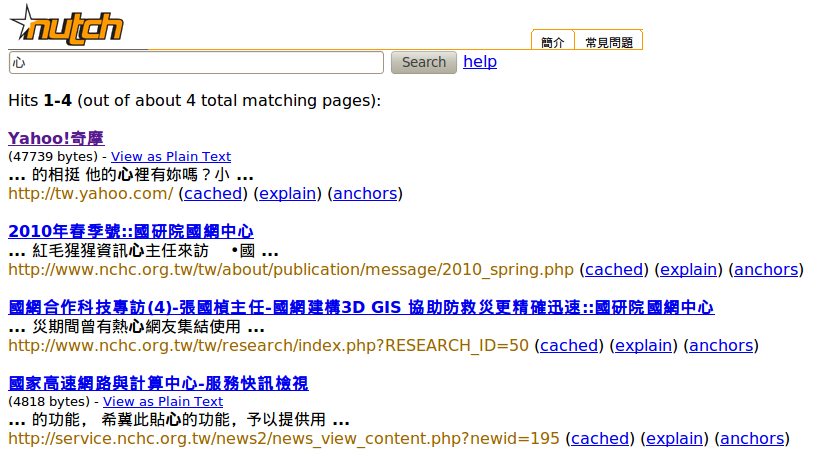
搜尋"中心"兩字 有74筆資料,但搜尋單一一個"心"字只有 4筆資料;反觀若是沒有經過中文分詞,則單搜尋"心"必定比搜尋"中心"的資料更多
- 搜尋 中心 這個字串

- 單搜尋 心 這個字

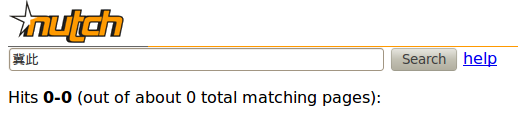
- 搜尋 "冀此" 或單獨 "冀" 都沒有資料

ps : 搜尋"希冀"才會有資料
方法
修改程式碼
- 安裝必要工具(java 已經安裝)
sudo apt-get install javacc unrar ant
- 修改NutchAnalysis.jj 約130行左右的程式碼 (原本為:| <SIGRAM: <CJK> >)
cd $nutch-1.0/ vim src/java/org/apache/nutch/analysis/NutchAnalysis.jj
| <SIGRAM: (<CJK>)+ >
- 用編譯器 javacc 編譯出七個java檔
CharStream.java NutchAnalysisTokenManager.java TokenMgrError.java NutchAnalysisConstants.java ParseException.java NutchAnalysis.java Token.java
cd $nutch-1.0/src/java/org/apache/nutch/analysis javacc -OUTPUT_DIRECTORY=./ika/ NutchAnalysis.jj mv ./ika/* ./ ; rm -rf ./ika/
- 編譯剛編出來的 NutchAnalysis?.java
vim $nutch-1.0/src/java/org/apache/nutch/analysis/NutchAnalysis.java
- 在第48行加入ParseException:
public static Query parseQuery(String queryString, Configuration conf) throws IOException,ParseException
- 在第54行加入ParseException:
throws IOException,ParseException {
- 下載 IKAnalyzer3.1.6GA.jar 解壓縮
- nutch 1.0 用的是 lucene 2.4.0 hadoop 0.19
- 因此ik分詞器最新僅能用 3.1.6ga (3.2.0GA 以上版本只支援lucene 2.9以上版本)
cd $nutch-1.0/ wget http://ik-analyzer.googlecode.com/files/IKAnalyzer3.1.6GA_AllInOne.rar mkdir ika unrar x ./IKAnalyzer3.1.6GA_AllInOne.rar ika/
- 分別放到以下三個資料夾
$nutch-1.0/lib/ 用來重新編譯nutch $my_nutch_dir/lib/ 用來給 nutch 進行 crawl時所匯入函式庫 $my_tomcat_dir/webapps/ROOT/WEB-INF/lib 用來給網頁的搜尋介面使用的函式庫
cp ika/IKAnalyzer3.1.6GA.jar lib/ cp $nutch-1.0/lib/IKAnalyzer3.1.6GA.jar $my_nutch_dir/lib/ cp $nutch-1.0/lib/IKAnalyzer3.1.6GA.jar $my_tomcat_dir/webapps/ROOT/WEB-INF/lib
- 修改 NutchDocumentAnalyzer.java 程式碼
cd $nutch-1.0/ vim src/java/org/apache/nutch/analysis/NutchDocumentAnalyzer.java
將
public TokenStream tokenStream(String fieldName, Reader reader) {
Analyzer analyzer;
if ("anchor".equals(fieldName))
analyzer = ANCHOR_ANALYZER;
else
analyzer = CONTENT_ANALYZER;
return analyzer.tokenStream(fieldName, reader);
}
修改成
public TokenStream tokenStream(String fieldName, Reader reader) {
Analyzer analyzer = new org.wltea.analyzer.lucene.IKAnalyzer();
return analyzer.tokenStream(fieldName, reader);
}
- 修改 build.xml,在 <include name="log4j-*.jar"/> 下(約195行),加入
cd $nutch-1.0/ vim build.xml
<include name="IKAnalyzer3.1.6GA.jar"/>
重編 nutch
- 重新編譯 nutch-1.0
ant
- 完成則多一個資料夾 build,
- build/ 目錄裡面的 nutch-job-1.0.job 就是重編後的核心
- 接著將 build/classes 內的程式碼打包起來,建立nutch-1.0-ika.jar 函式庫
- 補充:我有把預設的 nutch-site.xml 以及 nutch-default.xml放進去一起打包
cd $nutch-1.0/build/classes jar cvf nutch-1.0-ika.jar . cp nutch-1.0-ika.jar /opt/nutchez/nutch/lib/
開始使用
- 最後,將nutch-job-1.0.jar複製到我的nutchez資料夾內取代使用
- (下面的步驟小心的把原本的job作備份,也可以不用,改用新編出來的直接取代)
cd $nutch-1.0/ sudo mv $my_nutch_dir/nutch-1.0.job $my_nutch_dir/nutch-1.0-ori.job sudo cp build/nutch-1.0.job $my_nutch_dir/nutch-1.0-ika-waue-100715.job cp build/nutch-1.0.job sudo ln -sf $my_nutch_dir/nutch-1.0-ika-waue-100715.job $my_nutch_dir/nutch-1.0.job
- 把nutch-1.0.war(原本nutch附的即可),解壓縮後放在你的tomcat目錄內(以下用 $my_tomcat_dir 代表我tomcat的實際目錄)的/webapps/ROOT/中,並且再把"IKAnalyzer3.1.6GA.jar"、新編的 "nutch-1.0.jar" 放進 $my_tomcat_dir/webapps/ROOT/WEB-INF/lib 還有 $my_nutch_dir/lib/ 內
cd $nutch-1.0/ cp $nutch-1.0/build/ $my_nutch_dir/lib/ cd $my_tomcat_dir/webapps/ROOT/WEB-INF/lib cp $nutch-1.0/build/nutch-1.0.jar ./ cp $nutch-1.0/lib/IKAnalyzer3.1.6GA.jar ./
- 最後用nutch 的 crawl 抓取網頁,搜索的結果就是按ik分過的中文詞
完成
- 爬取後的資料就會依照中文分詞來分。
- 即使用原始的nutch所crawl下來的資料,將 重編後的nutch-1.0.jar nutch-1.0.job IKAnalyzer3.1.6 正確放到你原本的nutch搜尋網頁中,重新啟動tomcat後,也可直接享用有分詞的結果
- 中文分詞之後的結果並不會比較多,反而更少。但是精簡過後的搜尋結果才能提供更準確的搜尋內容。
Attachments (4)
- 1.png (162.6 KB) - added by waue 16 years ago.
- 2.png (107.5 KB) - added by waue 16 years ago.
- 3.png (13.7 KB) - added by waue 16 years ago.
- 4.png (46.5 KB) - added by waue 16 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip