
| Version 10 (modified by waue, 17 years ago) (diff) |
|---|
CloudBase
CloudBase 簡介
- cloudbase 為運用在hadoop的database,可以輕易的使用sql語法進行hadoop資料的分析。
- 每次進行sql的查詢時,hadoop就會進行mapreduce來解析,最後在呈現出結果。
- 與hbase的不同為,hbase必須在mapreduce的程式碼中加入把結果塞入hbase的程式碼;而cloudbase卻不用,只要將結果放在hdfs://user/$USER/cloudbase/data/$TABLE_Name/$TABLE_Name, 如:/user/waue/cloudbase/data/test_table1/test_table1 ,並且內容格式如下,即為cloudbase的資料檔
ipod|50|20.57|www.google.com ipod|10|10.25|www.google.com ipod|15|11.65|www.yahoo.com ipod|-20|-33.67|www.msn.com ipod|85|36.57|www.google.com zune|5|15.7|www.google.com zune|3|12.1|www.msn.com zune|10|6.5|www.msn.com iriver|30|15.5|www.yahoo.com iriver|45|12.3|www.yahoo.com iriver|25|16.7|www.yahoo.com iriver|15|15.3|www.yahoo.com iriver|20|18.0|www.yahoo.com iriver|16|20|www.google.com - CloudBase 提供了四種方法來讓使用者query資料 (http://cloudbase.sourceforge.net/index.html#userDoc)
- python (執行cloudbase提供的python的程式)
- java (用JDBC )
- cli (JiSQL )
- squirrel (圖形介面程式)
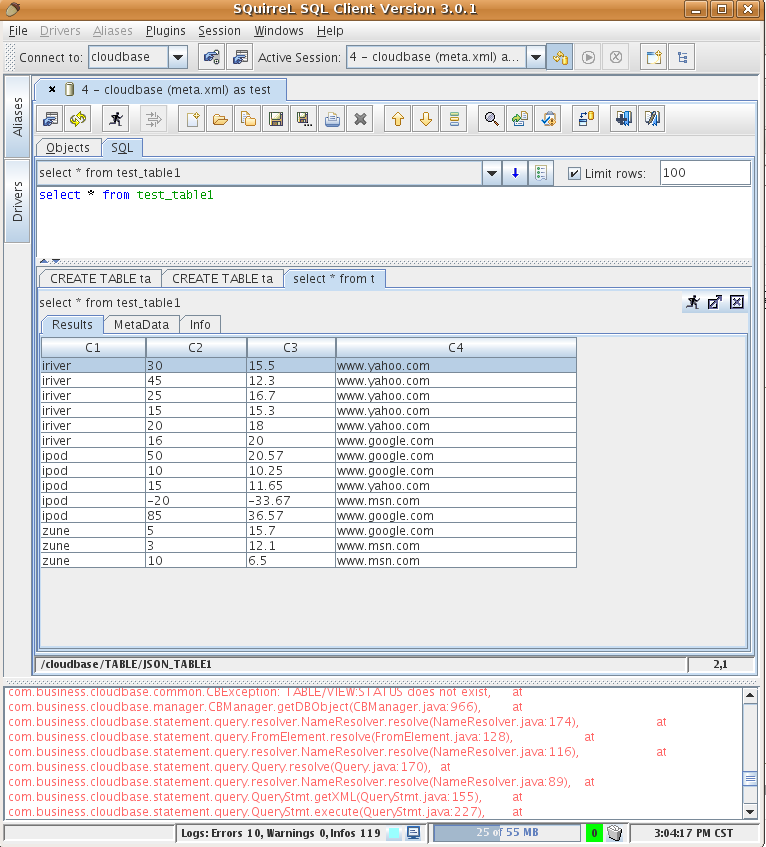
- 舉例來說,在squirrel執行 "select * from test_table1" 就出現如下結果

安裝步驟
step 0: 準備相關軟件:
下載hadoop-0.18.3.tar.gz
http://www.apache.org/dist/hadoop/core/hadoop-0.18.3/hadoop-0.18.3.tar.gz
下載cloudbase最新版(目前使用 cloudbase 1.3)
http://sourceforge.net/projects/cloudbase
http://downloads.sourceforge.net/cloudbase/cloudbase-1.3.tar.gz?use_mirror=jaist
step 1 : 安裝設定hadoop
- 請參考之前的hadoop安裝教學 或 nutch 的安裝教學
- 執行到start-all.sh ,亦即啟動hadoop環境並執行中...
- 確認服務正常:
$ jps 24376 NameNode 24471 DataNode 24579 SecondaryNameNode 24882 JobShell 24665 JobTracker 24769 TaskTracker 28090 Jps
step 2 : 啟動CloudBase
- 安裝cloudbase
$ cd /opt/ $ tar xvzf cloudbase-1.3.tar.gz $ ln -sf /opt/cloudbase-1.3 /opt/cloudbase
- 修改 cloudbase-env
$ vim /opt/cloudbase/bin/cloudbase-env
- 內容為:
# Set the hadoop home dir HADOOP_HOME=/home/hadoop/hadoop export HADOOP_HOME
- 內容為:
- 啟動 cloudbase
$ cd /opt/cloudbase/bin/ $ ./start-cloudbase &
- 記得執行$cloudbase/test/bin/setup 以建立測試的資料表(此步驟連官網都沒有,但最後一直沒有test_table出現,找了很久才找到要執行此步)
step 3 : 用SQuirreL SQL 檢視
- 首先下載client 端軟件,SQuirreL SQL Client 。
- 執行點擊兩下下載下來的 squirrel-sql-3.0-install.jar即可安裝,下一步即可
- 執行squirrel ,跑出主程式頁面,並執行以下操作
- Drivers -> New Driver ->
name CloudBase JDBC Driver example url jdbc:cloudbase://localhost:4444 class name com.business.cloudbase.CBDriver ultra class path /opt/cloudbase/build/jar/cloudbasejdbc-1.3.jar -> ok
- Aliases ->
user test password test -> connect
- SQL -> select * FROM test_table1 -> 點小黑人在跑的圖示 -> 就有結果出現囉!
}}}
- enjoy
- 當執行sql語法時,可以到localhost:50030觀查到,hadoop被呼叫來執行mapreduce的工作。而cloudbase的console端也能看到完整的log如下
GOT SQL: select t1.c1, t1.c2, t1.c3, t1.c4, t2.c1, t2.c2, t2.c3, t2.c4 from test_table4 t1 inner join test_table5 t2 on t1.c1 = t2.c1 order by 1,2,3,4,5,6,7,8 09/05/05 14:12:07 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 09/05/05 14:12:07 INFO mapred.FileInputFormat: Total input paths to process : 1 09/05/05 14:12:07 INFO mapred.FileInputFormat: Total input paths to process : 1 09/05/05 14:12:07 INFO mapred.JobClient: Running job: job_200905010939_0030 09/05/05 14:12:08 INFO mapred.JobClient: map 0% reduce 0% 09/05/05 14:12:12 INFO mapred.JobClient: map 100% reduce 0% 09/05/05 14:12:17 INFO mapred.JobClient: Job complete: job_200905010939_0030 09/05/05 14:12:17 INFO mapred.JobClient: Counters: 16 09/05/05 14:12:17 INFO mapred.JobClient: File Systems 09/05/05 14:12:17 INFO mapred.JobClient: HDFS bytes read=207 09/05/05 14:12:17 INFO mapred.JobClient: HDFS bytes written=461 09/05/05 14:12:17 INFO mapred.JobClient: Local bytes read=159 09/05/05 14:12:17 INFO mapred.JobClient: Local bytes written=404 ~~~~ 略 ~~~~~ 09/05/05 14:14:21 INFO mapred.JobClient: Job Counters 09/05/05 14:14:21 INFO mapred.JobClient: Launched map tasks=2 09/05/05 14:14:21 INFO mapred.JobClient: Data-local map tasks=2 09/05/05 14:14:21 INFO mapred.JobClient: Map-Reduce Framework 09/05/05 14:14:21 INFO mapred.JobClient: Map input records=7 09/05/05 14:14:21 INFO mapred.JobClient: Map input bytes=201 09/05/05 14:14:21 INFO mapred.JobClient: Map output records=7
Attachments (1)
- 2009-05-05-150417_766x847_scrot.png (96.1 KB) - added by waue 17 years ago.
{kind=link}
Download all attachments as: .zip