
| Version 6 (modified by shunfa, 16 years ago) (diff) |
|---|
Crawlzilla 網頁執行介面
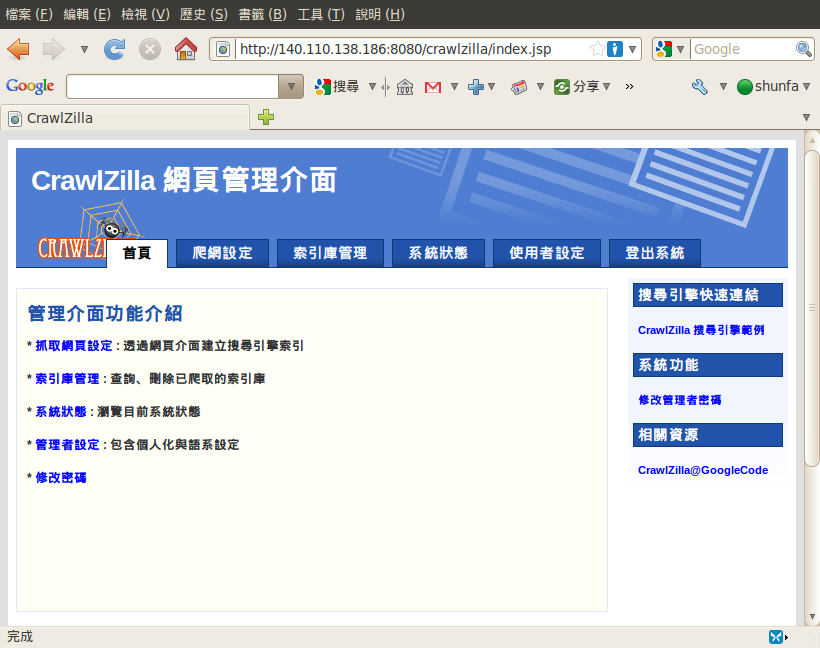
管理介面預設網址為:http://localhost:8080 或 http://ServerIP:8080,登入後首頁如下:

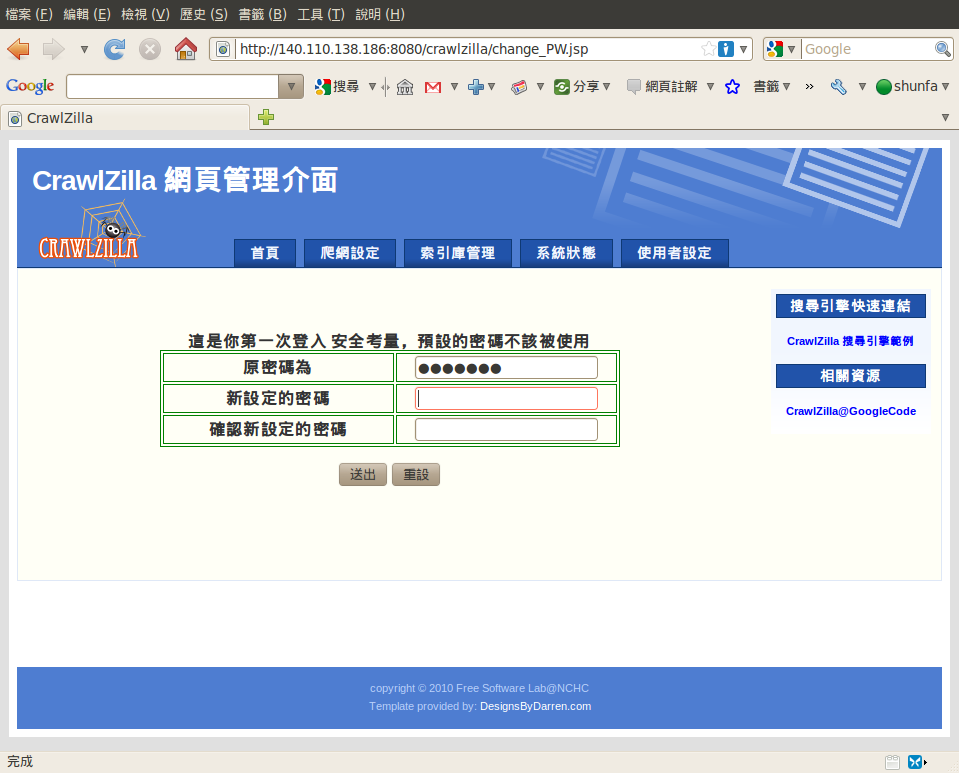
設定網頁管理者密碼
首次進入網頁介面時,必須先重設管理者密碼(預設密碼為:crawler),設定密碼點選送出並重新登入後就可執行系統。

建立第一個搜尋引擎
Step1. 開啟所有運算服務
由於執行Crawl必須透過Hadoop運算,因此執行Crawl前請先依序確認以下服務是否已開啟,若為關閉狀態,請依序開啟這些服務。
- Namenode and Jobtracker
- Datanode and Tasktracker(需開啟全部的運算節點)
若不熟悉開啟步驟,請參考系統管理介面操作說明
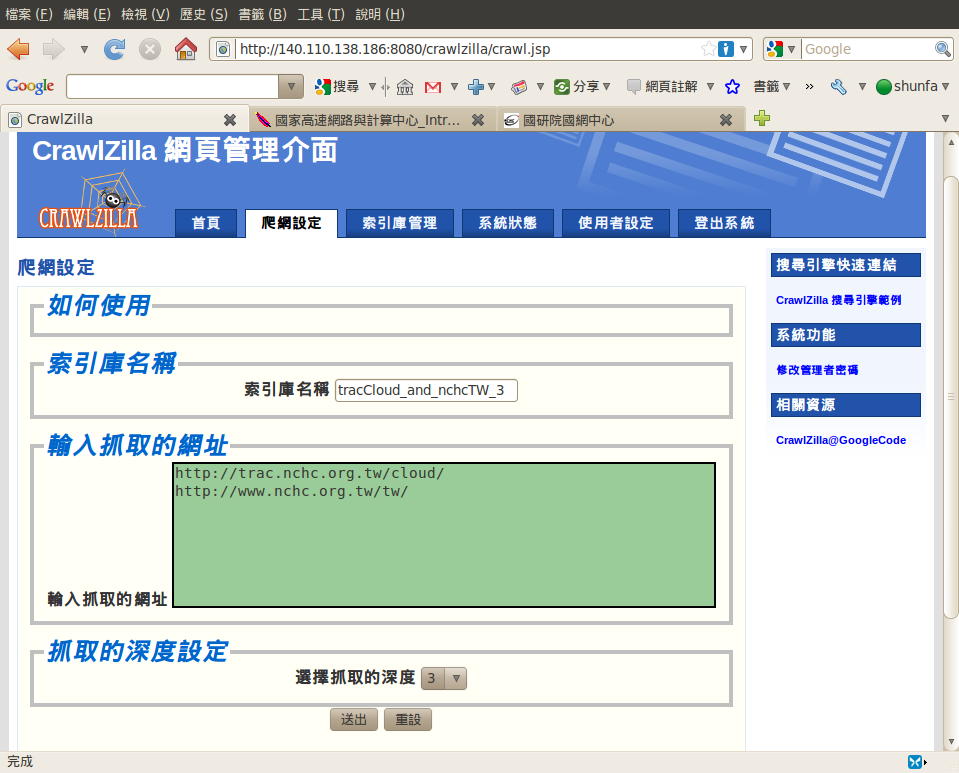
Step2. 至Crawl網頁中設定爬取項目
依序填入:索引庫名稱,欲抓取的網址(可多行,如圖所示)及設定爬取深度即可送出

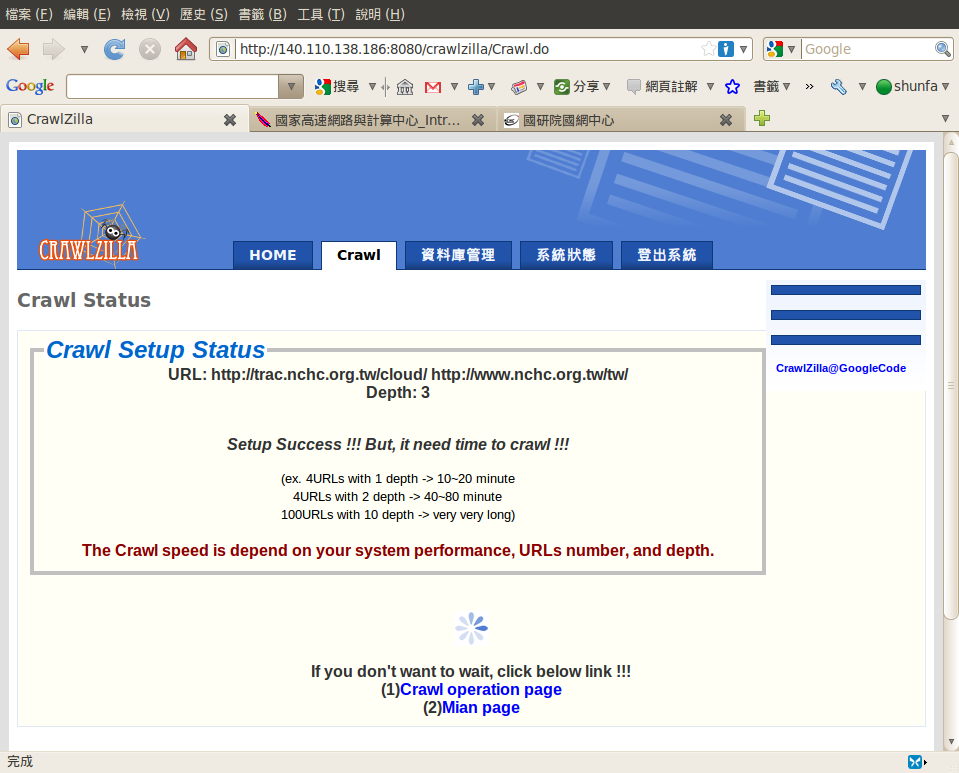
送出後如圖所示,等候時間需視視每台主機的運算速度而定。

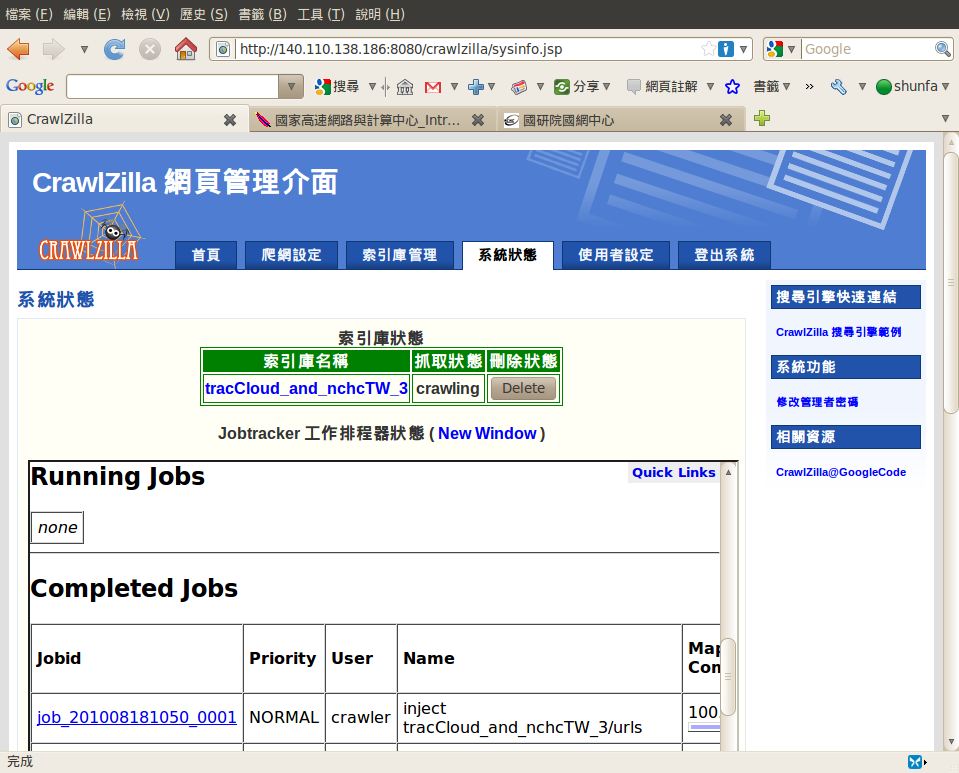
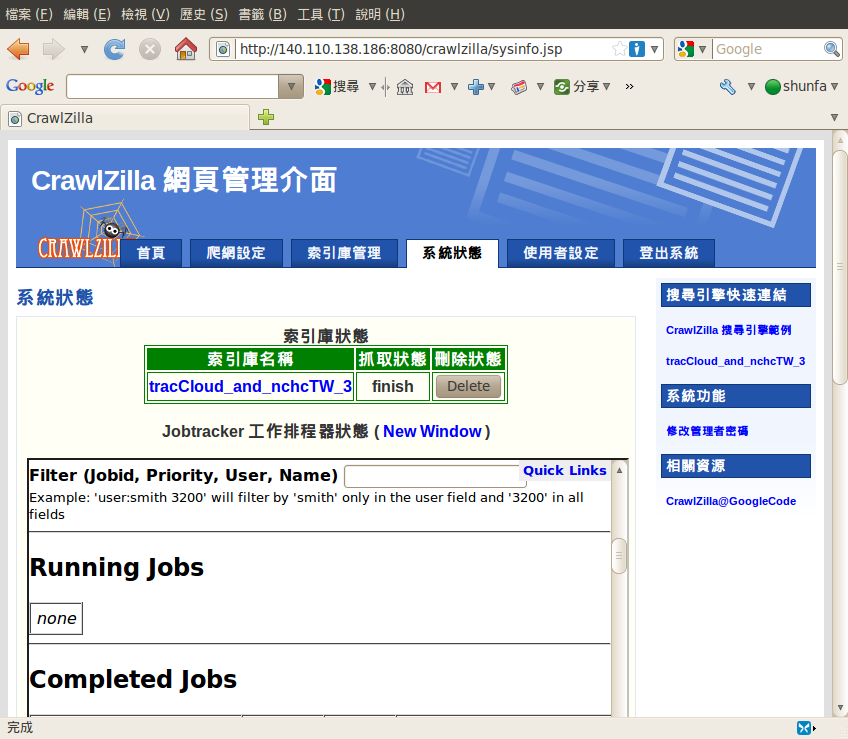
Step3. 瀏覽網頁爬取進度
透過系統狀態頁面,可即時了解網頁爬取進度

待出現"Finish"表示索引庫已建立,並可將此一訊息刪除

- 完成此一步驟,第一個搜尋引擎已建置,右側快速連結中的"tracCloud_and_nchcTW_3"即為此次所建立的搜尋引擎。
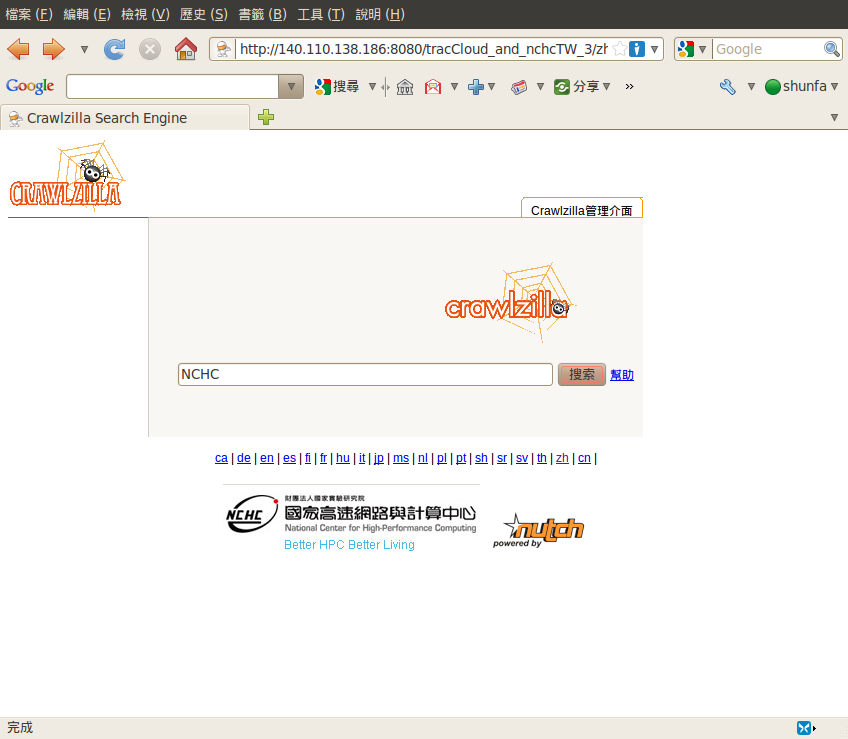
Step4. 測試搜尋引擎功能
點選右側快速連結中的"tracCloud_and_nchcTW_3"進入搜尋引擎後,輸入一組關鍵字測試搜尋結果,下圖為輸入"nchc"為例:

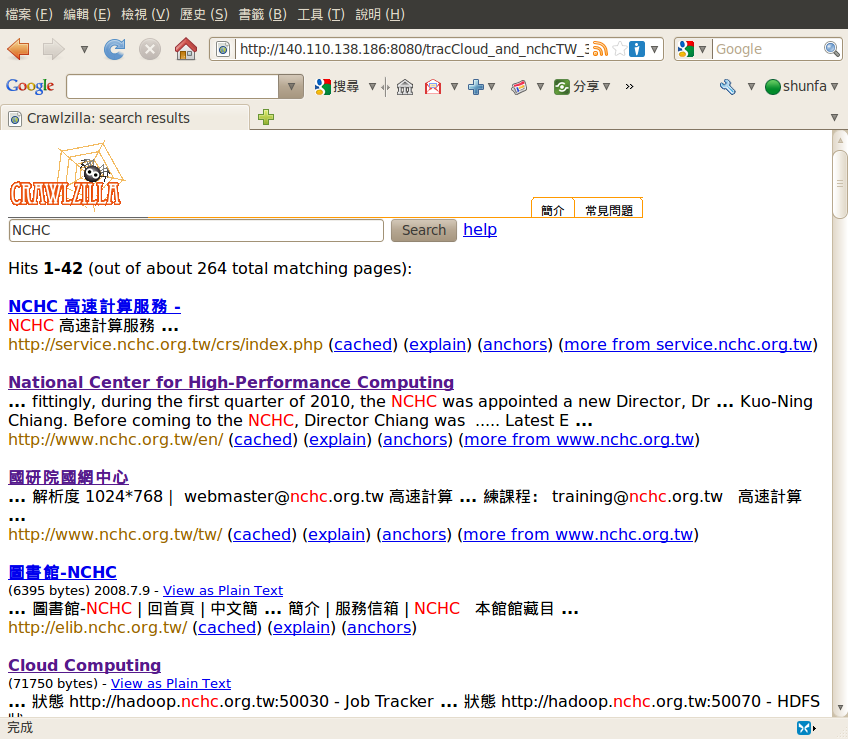
搜尋結果:

其他功能
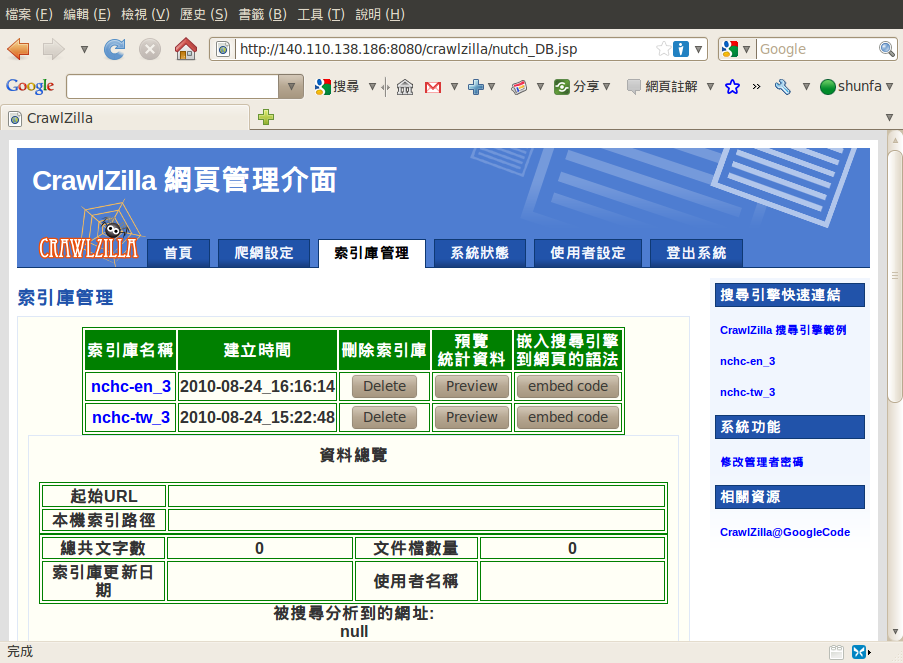
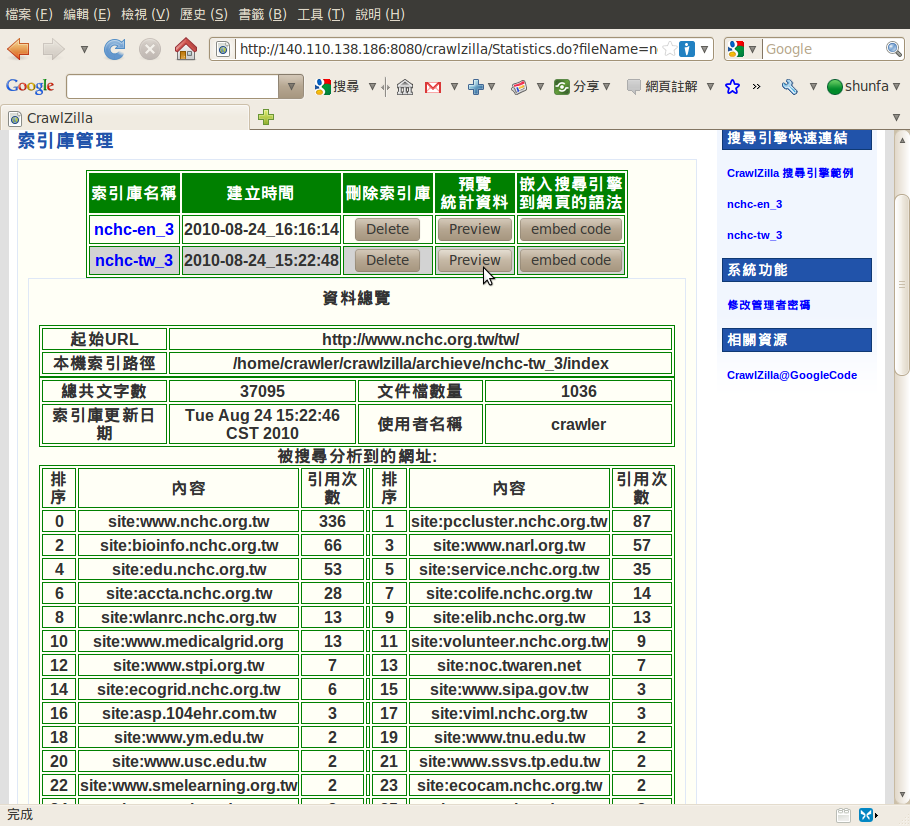
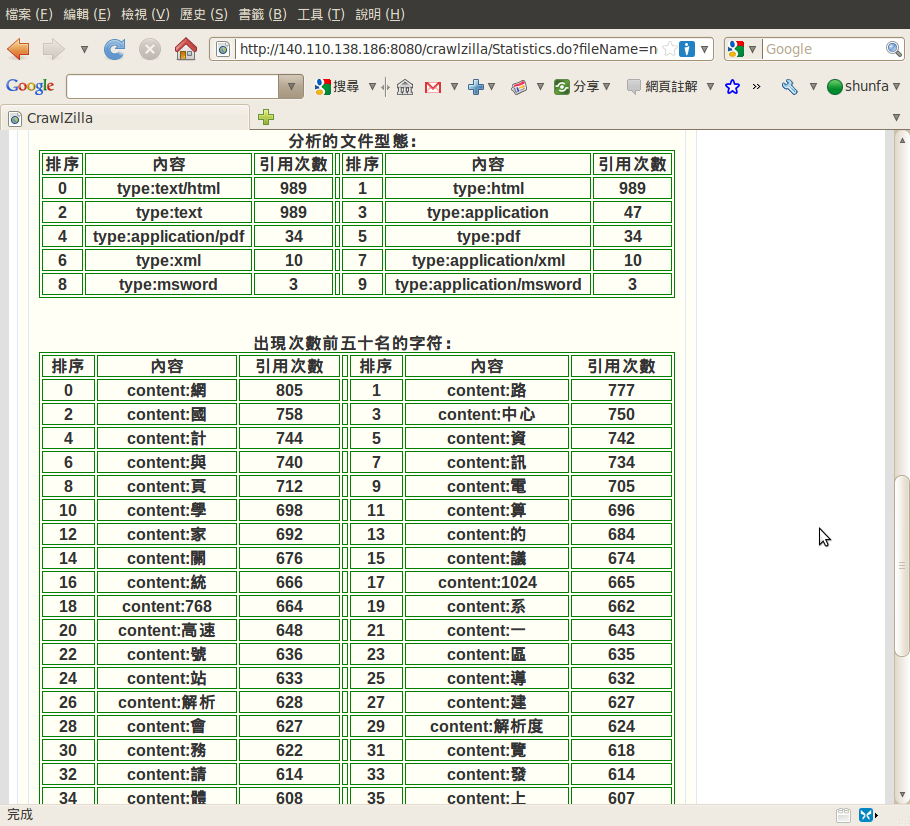
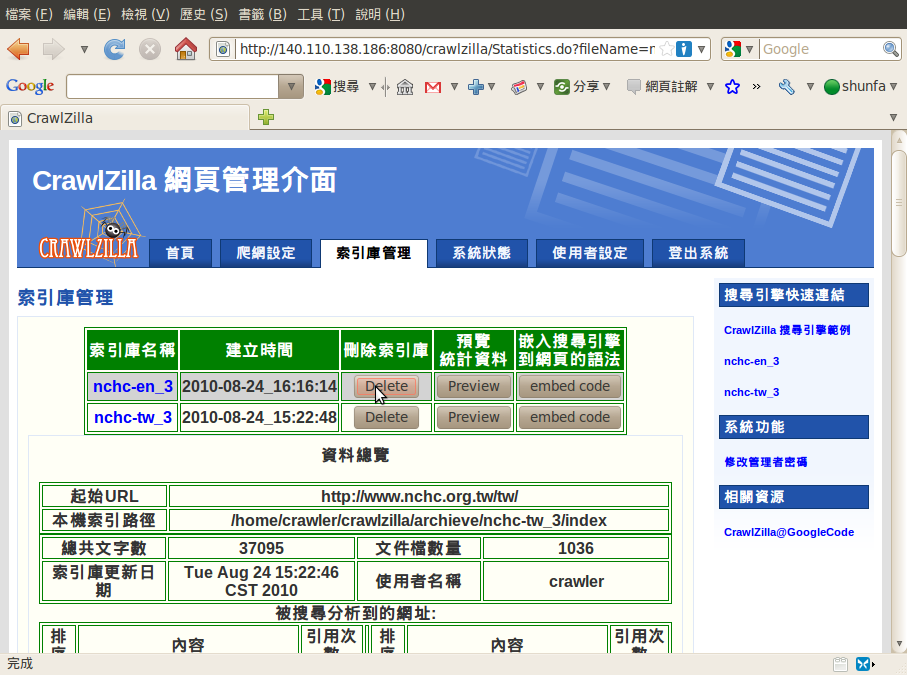
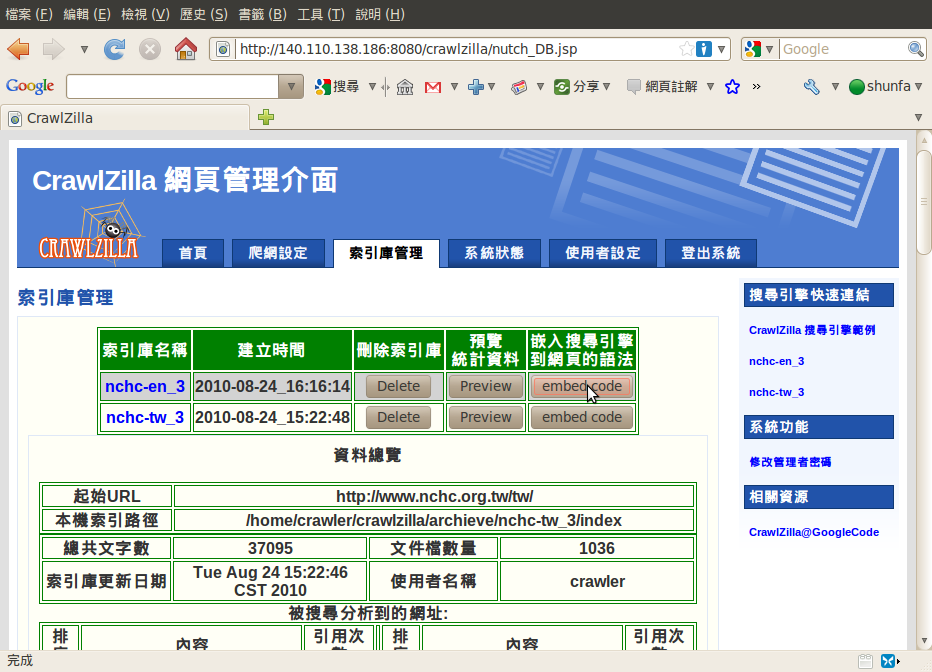
索引庫管理
索引庫瀏覽
索引庫刪除
網頁多工爬取
同時存在多個搜訊引擎
在網頁中嵌入搜尋引擎
last modified: 2010/08/20
Attachments (14)
- 2.png (115.7 KB) - added by shunfa 16 years ago.
- 3.png (141.9 KB) - added by shunfa 16 years ago.
- 4.png (117.9 KB) - added by shunfa 16 years ago.
- 5.png (146.4 KB) - added by shunfa 16 years ago.
- 1.png (113.1 KB) - added by shunfa 16 years ago.
- 6.png (130.4 KB) - added by shunfa 16 years ago.
- 7.png (84.5 KB) - added by shunfa 16 years ago.
- 8.png (137.7 KB) - added by shunfa 16 years ago.
- 9.png (148.1 KB) - added by shunfa 16 years ago.
- 10.png (185.3 KB) - added by shunfa 16 years ago.
- 11.png (151.6 KB) - added by shunfa 16 years ago.
- 12.png (166.1 KB) - added by shunfa 16 years ago.
- 14.png (164.9 KB) - added by shunfa 16 years ago.
- 15.png (18.3 KB) - added by shunfa 16 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip