
hadoop4win
-- Hadoop for Windows using Cygwin
軟體簡介
hadoop4win,顧名思義為『Hadoop for Windows』,主要是提供 Windows 平台上簡易安裝 Hadoop 的批次安裝檔。此批次安裝檔內容,主要參考自國網中心企鵝龍與再生龍團隊成員孫振凱先生之 drbl-winroll 作品,抽取安裝部分程式改寫成 hadoop4win 所需的步驟。
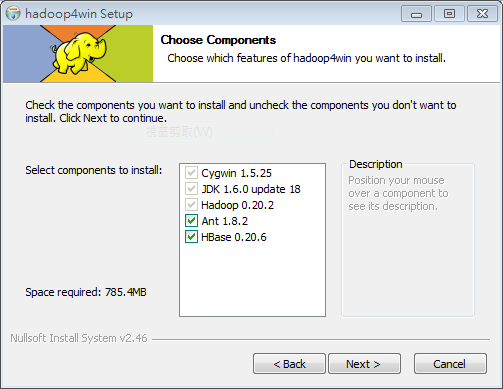
hadoop4win 目前包含五大軟體組成:
- Cygwin - 提供精簡版,類似 Linux 的環境
- JDK 1.6.0 update 18 - 運行 Hadoop 必須的 JRE(Java Runtime Environment) 與編譯程式所需之 javac 編譯器
- Hadoop 0.20.2 - 包含 Hadoop 0.20.2 原始程式與中英文說明文件檔
- HBase 0.20.6 - 包含 HBase 0.20.6 原始程式碼
- Ant 1.8.2 - 包括 Apache Ant 1.8.2 執行檔
硬體需求
- 已知最低 512 MB 記憶體需求,建議至少 1024 MB。
- 安裝相關軟體至少需要 500 MB 以上硬碟空間。
軟體需求
- Windows 2000, Windows XP, Windows 2003 (Tested on hiCloud)
- 已知 Windows 7 須關閉 UAC 才有辦法正常安裝。 關閉方法請參閱網路文件。但目前仍經常有無法成功安裝的案例,原因待查。
軟體授權
- Apache 2.0 + GPL
- 由於 Cygwin 的授權是 GPL,而 Hadoop, Pig, HBase 是 Apache 授權,因此本軟體採用雙重授權方式釋出。
- 關於 Sun JDK 部份未來若有爭議,將改採從官方下載方式釋出。
檔案下載
- 0.1.5 alpha
- 0.1.4 alpha
- 0.1.3 alpha
- 0.1.2 alpha
- 0.1.0 alpha
源碼下載
- 0.1.0 ~ 0.1.4 檔案壓縮檔本身就包含所有必備的程式(包括 hadoop4win-setup.bat 批次檔是 Windows Shell Script,以及 my_packages/*/bin 底下的 *-init 是 Bash Shell Script)
- 0.1.5 可以下載 hadoop4win-nsis_0.1.5_src.zip(181 MB)
- 0.1.5 的原始碼必須在 Windows 底下安裝 NSIS 才能透過 MakeNSISW 進行編譯。
- 備註:若想在 Linux 底下用 makensis 產生安裝檔,可能會因為 files 與 cygwin_mirror 目錄下的檔案格式不合而出錯。
改版紀錄
- 0.1.5 alpha - 2011/05/03 :
- 改用 NSIS 撰寫 Windows 安裝程式。
- 新增「開始選單」與「反安裝程式」。
- 修改 hadoop4win-init 安裝流程:
- 自動產生 conf-pseudo 目錄內容,並將原本預設設定目錄移到 conf-local 中。
- 這個做法可以解決 Win7 先前遇到的權限問題。
- 0.1.4 alpha - 2011/03/28 :
- 更新 %HBASE_MIRROR 檔案下載網址,並將 %HBASE_FILE 版本更新至 0.20.6
- 新增 Ant 編譯工具,新增 %ANT_MIRROR 與 %ANT_FILE 至安裝批次檔。新增 ant-init 安裝流程。
- 修正 $HADOOP_HEAPSIZE 到 256 MB,以降低記憶體需求。
- 註: 在許多低於 1GB 記憶體環境,可修正 hadoop-env.sh 中的 HADOOP_HEAPSIZE 到 128 MB。
- 修正 hadoop4win-init 安裝流程:
- 用拷貝(cp)取代鍊結(symbolic link)
- 強制離開 Safe Mode,以縮短 Hadoop 0.20.2 的 HDFS 檢查費時 30 秒時間。
- 修正 hbase-init 安裝流程:
- 設定 ${hbase.tmp.dir} 與 $HBASE_PID_DIR 到 /var/hbase 目錄
- 0.1.3 alpha - 2010/05/26 :
- 感謝 NKZ (ccliangnn) 於 hadoop forum 回報 URL 下載連結失效,逼懶惰的作者更新程式。
- 更新網路安裝版,安裝批次檔中的檔案下載網址:HADOOP_MIRROR、HADOOP_FILE、JDK_MIRROR
- 不用再打 hbase-init 來安裝 HBase,這一版是預設 HBase 直接安裝了。
- 新增一些判斷在 start-*, stop-* 的 script,例如:start-hbase會根據 hadoop 是否啟動,判斷是否幫忙執行 start-hadoop。
- 0.1.2 alpha - 2010/02/06 :
- 改回 Cygwin 1.5.25 版本的套件庫 - 感謝 Yi-Kai Tsai 回報 0.1.1 版無法正確執行 wordcount 範例的 BUG
- 0.1.1 alpha - 2010/02/04 :
- 改用 Cygwin 1.7.1 版本的套件庫 - 並且改用 "-P" 參數指定欲額外安裝套件
- 修改 hadoop4win-setup.bat 批次檔,以因應 Cygwin 1.7 版本的 setup.exe 差異。
- 新增 HADOOP_HOME、HADOOP_CLASSPATH、HADOOP_CONF_DIR 環境變數至 hadoop-env.sh - 感謝 Yi-Kai Tsai 建議
- 新增 /opt/hadoop/bin 與 $JAVA_HOME/bin 到 /etc/profile 的 PATH 環境變數,讓每個使用者可以簡單輸入 hadoop 指令 - 感謝 Yi-Kai Tsai 建議
- 修改 start-hadoop 並加入 start-hadoop-daemon 命令,另行開一視窗啟動 HDFS Name Node、Data Node 與 MapReduce Job Tracker、Task Tracker 子程序。如此一來可以避免 CTRL+C 觸發 SIGINT 而強制停止所有 java 程序。 - 感謝 Yi-Kai Tsai 找出重現 BUG 的主因(Ctrl+C)
- 新增 stop_hadoop 指令至 ~/.bash_logout 與 /etc/skel/.bash_logout,以確保離開 Cygwin 時關閉 HDFS 與 MapReduce -- 若要保留 java 程序,可手動移除
- 新增 hbase-init、start-hbase、start-hbase-daemon、stop-hbase 來初始化 hbase 下載、安裝、設定、啟動 ZooKeeper、Master、RegionServer 的程序。
- 0.1.0 alpha - 2010/01/22
- 基於 drbl-winroll 修改為 hadoop4win 嚐鮮版
臭蟲回報
- 請至 http://forum.hadoop.tw 的 "hadoop 安裝與設定"討論區
- 最新訊息請參閱: http://trac.nchc.org.tw/cloud/wiki/Hadoop4Win
- 專案網站
- 建議新功能或臭蟲回報 - http://code.google.com/p/hadoop4win/issues/list
安裝方法 (1) 安裝檔
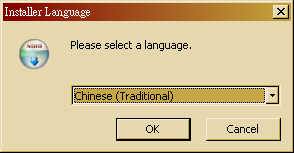
- STEP 1 : 點選 hadoop4win 安裝檔(*.exe),首先請選擇語系:(預設是「正體中文」)
- STEP 2 : 本軟體採 Apache 授權,按下「我接受(I Agree)」按鈕繼續。
- STEP 3 : 預設一定會安裝 Cygwin 、JDK 與 Hadoop ,至於 HBase 跟 Ant ,您可視需求自行取消。
- STEP 4 : 指定安裝目錄(預設是 C:\hadoop4win),請確認安裝目錄有寫入權限。
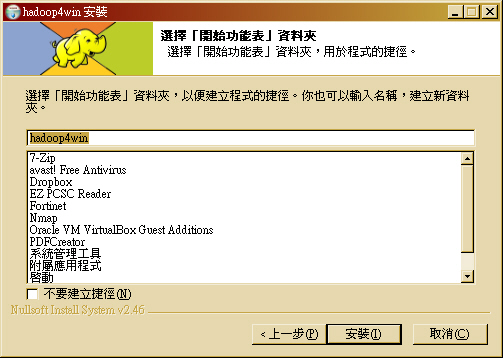
- STEP 5 : 指定「開始功能表」的目錄名稱,預設為 hadoop4win,稍候會建立一些常用的捷徑。
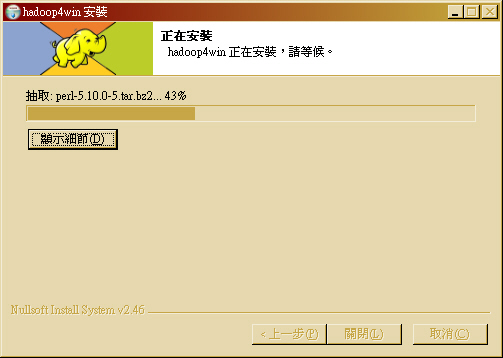
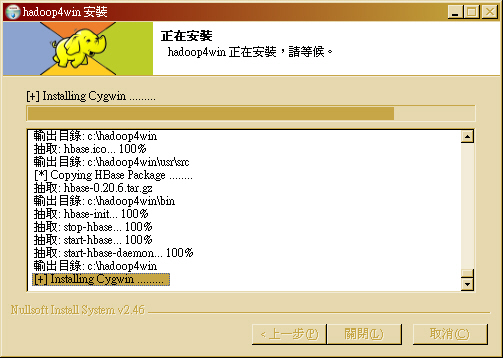
- STEP 6 : 開始安裝,可按下「顯示細節」看目前的安裝進度。
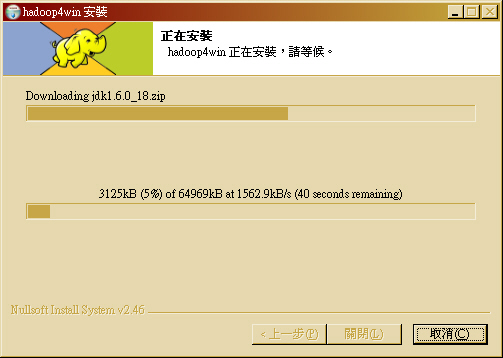
- 若為網路安裝版,會顯示下載 JDK、Hadoop、Ant 與 HBase 的下載進度訊息
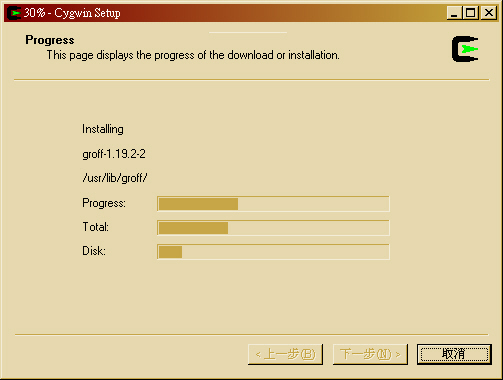
- 接著會自動安裝 Cygwin
- 當 Cygwin 安裝完成後,會在「顯示細節」的安裝進度中,看到在解壓縮 Hadoop 、Ant 與 HBase 的進度。
- 安裝完成時,可看到幫您設定好「開始功能表」的一些捷徑
- 目前在「開始功能表」設定了以下的捷徑:

- hadoop4win - 啟動 hadoop4win 的 Cygwin 視窗
- start-hadoop - 啟動 Hadoop 的服務(跑在獨立的 CMD 視窗中)
- start-hbase - 啟動 HBase 的服務(跑在獨立的 CMD 視窗中),請先跑 start-hadoop 才跑 start-hbase
- stop-hadoop - 關閉 Hadoop 的服務(請關閉 HBase 之後才關閉 Hadoop)
- stop-hbase - 關閉 HBase 的服務
- Hadoop API javadoc - 開啟安裝在本機的 Hadoop API 文件
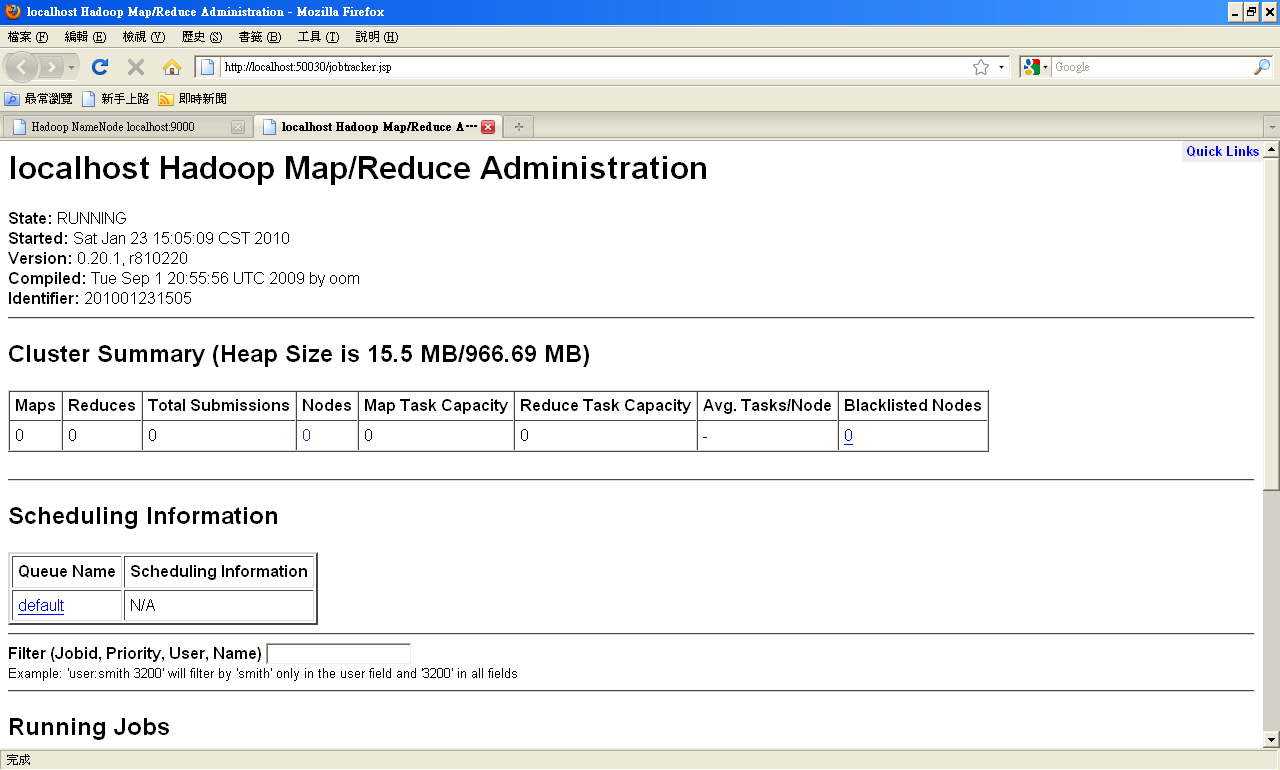
- JobTracker Web UI - 用瀏覽器開啟 http://localhost:50030 的頁面
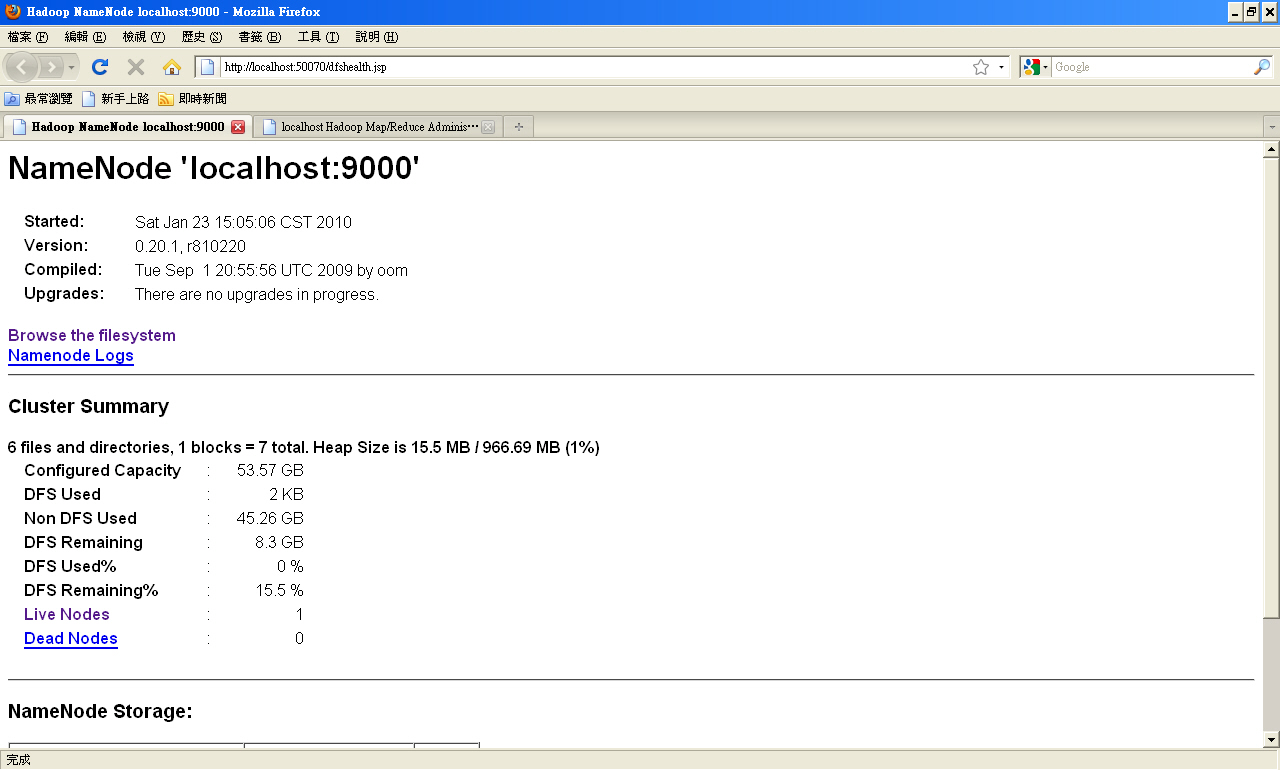
- NameNode Web UI - 用瀏覽器開啟 http://localhost:50070 的頁面
- uninstall - 反安裝程式












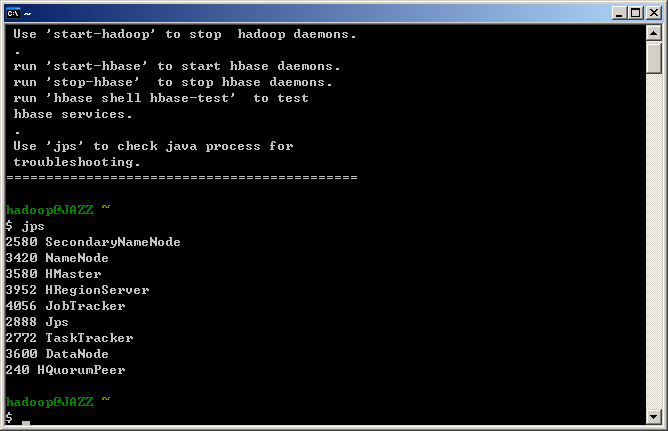
- 若您在 Windows 7 底下無法看到 jps 的結果,欲啟動 Hadoop 請執行以下指令:
taskkill /f /im java.exe /opt/hadoop/bin/hadoop-daemon.sh start namenode /opt/hadoop/bin/hadoop-daemon.sh start secondarynamenode /opt/hadoop/bin/hadoop-daemon.sh start datanode /opt/hadoop/bin/hadoop-daemon.sh start jobtracker /opt/hadoop/bin/hadoop-daemon.sh start tasktracker
- 若要關閉 Hadoop 的所有服務,請使用以下指令
/opt/hadoop/bin/hadoop-daemon.sh stop tasktracker /opt/hadoop/bin/hadoop-daemon.sh stop datanode /opt/hadoop/bin/hadoop-daemon.sh stop secondarynamenode /opt/hadoop/bin/hadoop-daemon.sh stop jobtracker /opt/hadoop/bin/hadoop-daemon.sh stop namenode
安裝方法 (2) 批次檔
- STEP 1 : 首先下載 hadoop4win 任一版本,並存至硬碟(如 D:)。使用 Windows XP 以上版本內建的解壓縮工具將 zip 壓縮檔解開。
- STEP 2 : 在 hadoop4win-setup 目錄中,執行 hadoop4win-setup.bat 批次檔。
- 註:預設將安裝到 C:/hadoop4win 中,若因硬碟存取權限較嚴格,需修改安裝路徑,請自行修改 hadoop4win-setup.bat。


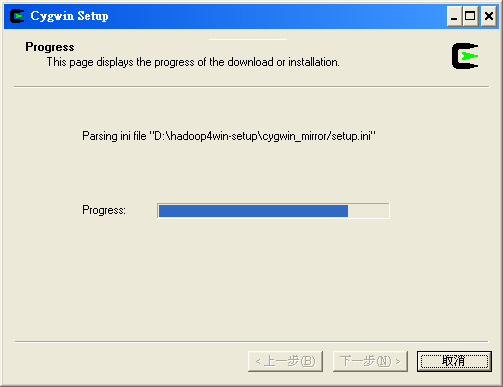
- STEP 3 : 一開始會出現 Cygwin 的安裝畫面,按『下一步(N)』開始安裝。

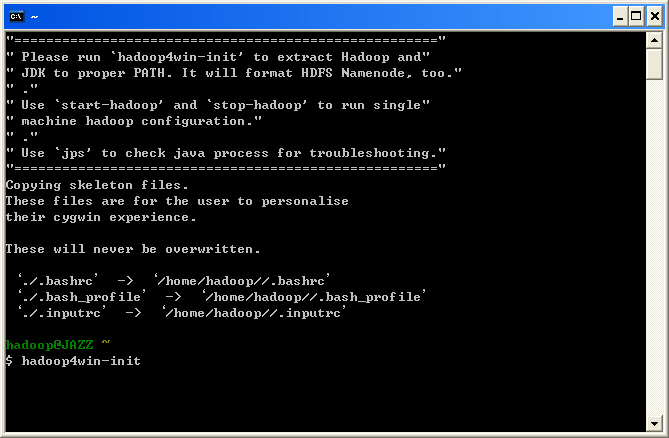
- 接著批次程式將會把 Hadoop 單機版所需之 Java 開發環境 (JDK 1.6.0 update 18)、 Hadoop 0.20.2、 Ant 1.8.2 與 HBase 0.20.6 壓縮檔拷貝至安裝目錄 /usr/src。若您下載的是網路安裝版本,會看到批次檔先從網路上下載四個壓縮檔,才開始安裝。

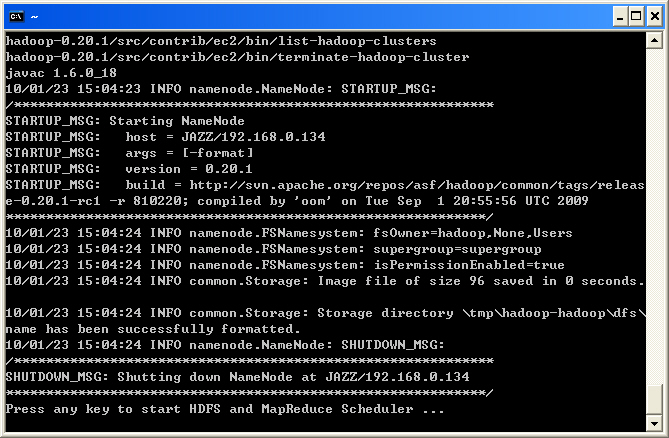
- 程式會自動執行 JDK 與 Hadoop 的安裝。


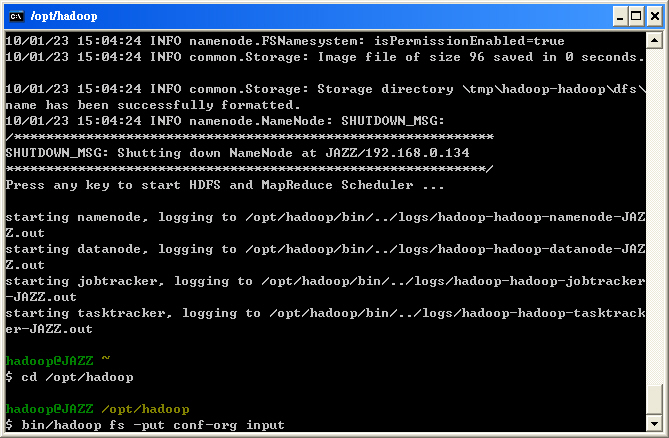
- 並且幫您自動執行 Hadoop Namenode 的格式化

- 隨即依序啟動 Hadoop Name Node, Data Node, Job Tracker, Task Tracker

- 並使用預設瀏覽器依序開啟 http://localhost:50030 與 http://localhost:50070 (若使用 IE 可能會只看到一個畫面,Firefox 則會看到兩個分頁)


- 其次會解壓縮 Ant,並安裝至 /opt/ant 中。
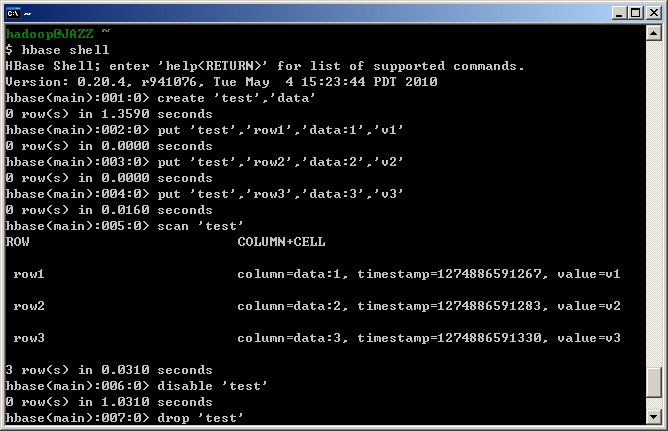
- 最後會解壓縮 HBase,並進行單機版 HBase 的設定,當完成 HBase 安裝後,您會看到以下的畫面。


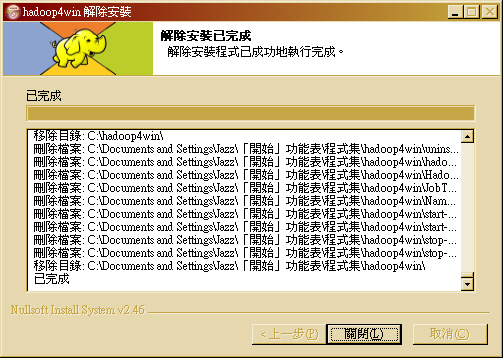
反安裝方法 (1) 安裝檔
- 在「開始功能表」點選 uninstall 捷徑,執行反安裝程式,接著按下「移除」。
- 反安裝程式就會開始進行解除安裝的步驟,請先確定 Hadoop 與 HBase 是停止狀態(stop-hadoop & stop-hbase),否則會有部份檔案無法移除的問題。
- 移除完畢後,可點選「顯示細節」,看整個反安裝歷程。



- 註:由於 C:/var 中存放了 Hadoop NameNode 與 DataNode 的資料,目前不會自動幫各位清除,若不需要保留,請自動清除!!
反安裝方法 (2) 批次檔
- 首先,請先確定 Hadoop 與 HBase 是停止狀態(stop-hadoop & stop-hbase),否則會有部份檔案無法移除的問題。
- 接著只要開啟檔案總管,將安裝目錄(如:C:\hadoop4win)刪除,以及同磁碟的 var 目錄(若安裝在 C:\hadoop4win 則會出現在 C:\var)加以移除。
- 註:由於 var 中存放了 Hadoop NameNode 與 DataNode 的資料,清除前請確認是否有重要資料!!
測試方法
測試 Hadoop 的步驟
- STEP 4 : 此時系統已完成 Hadoop 0.20.2 的 tar ball 安裝,可以參考 國網中心雲端運算課程(一) 之教學進行相關測試。目前將 Hadoop 0.20.2 安裝於 /opt/hadoop 路徑下,故使用者必須先切換至該目錄才能進行相關指令操作。
$ cd /opt/hadoop
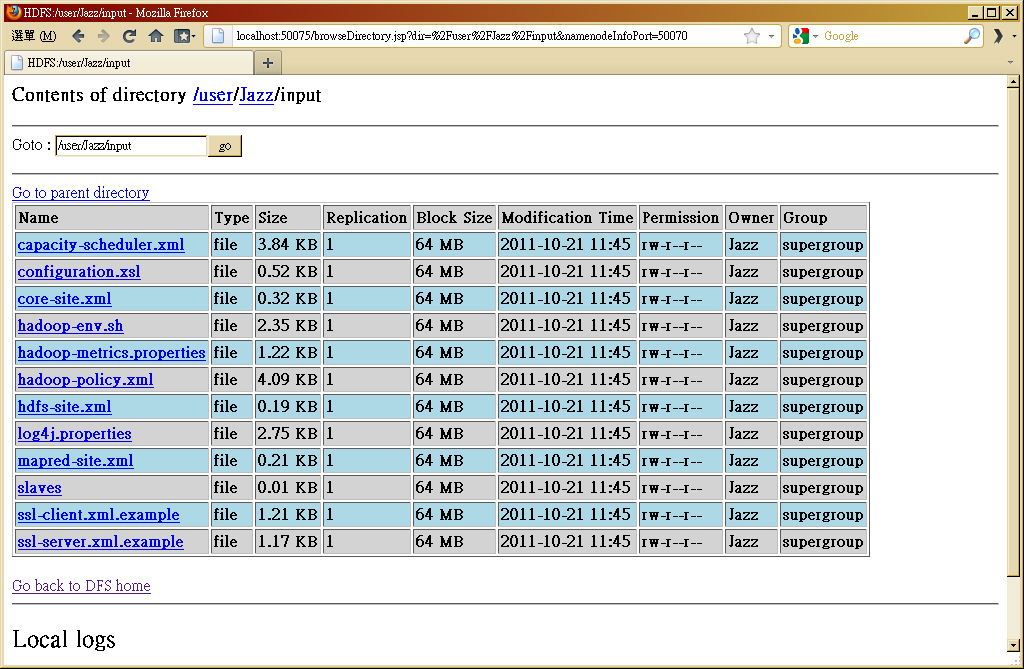
- STEP 5 : 練習 HDFS 指令: 『bin/hadoop fs -put <local file/dir> <HDFS file/dir>』
$ bin/hadoop fs -put conf-pseudo input

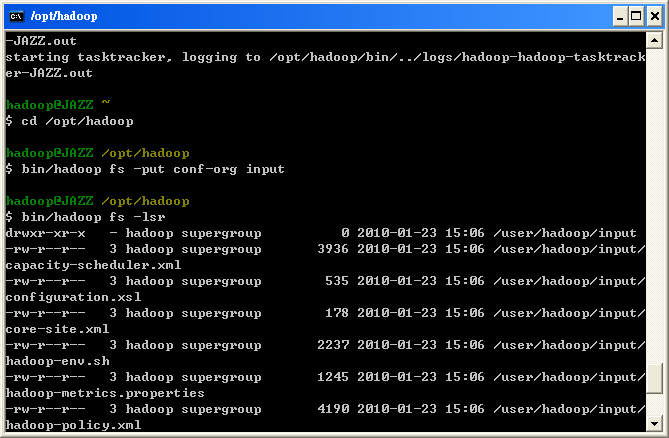
- STEP 6 : 練習 HDFS 指令: 『bin/hadoop fs -lsr <HDFS file/dir>』
$ bin/hadoop fs -lsr

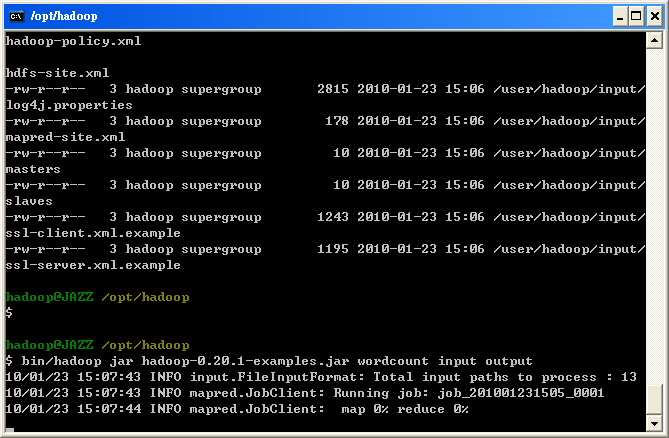
- STEP 7 : 練習 MapReduce 丟 Job 指令: 『bin/hadoop jar <local jar file> <class name> <parameters>』
$ bin/hadoop jar hadoop-*-examples.jar wordcount input output

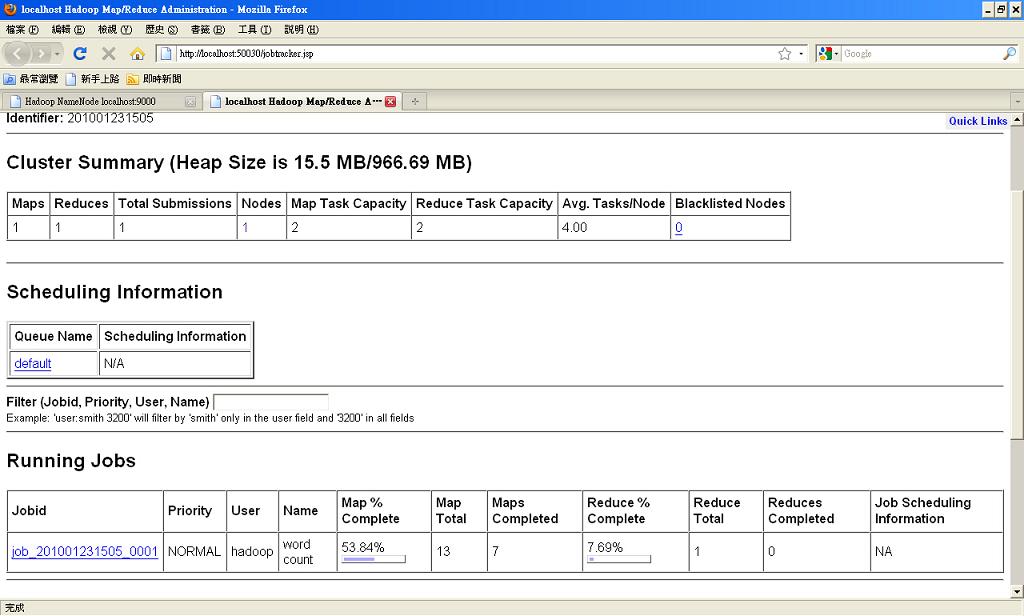
- STEP 8 : 練習從 http://localhost:50030 查看目前 MapReduce Job 的運作情形

- STEP 9 : 練習 HDFS 指令: 『bin/hadoop fs -get <HDFS file/dir> <local file/dir>』,並了解輸出檔案檔名均為 part-r-*,且執行參數會紀錄於 <HOSTNAME>_<TIME>_job_<JOBID>_0001_conf.xml,不妨可以觀察 xml 內容與 hadoop config 檔的參數關聯。
$ bin/hadoop fs -get output my_output $ ls -alR my_output

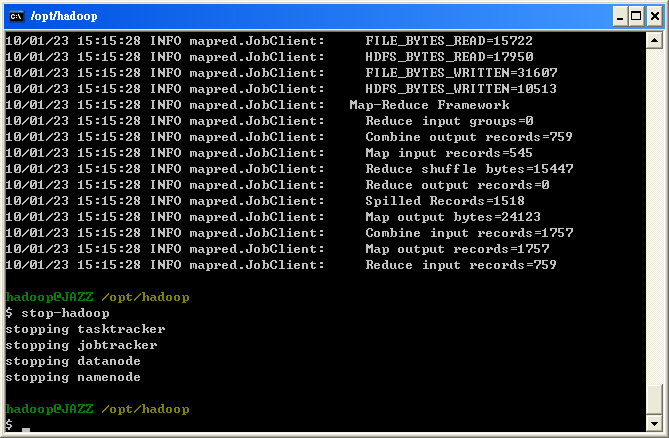
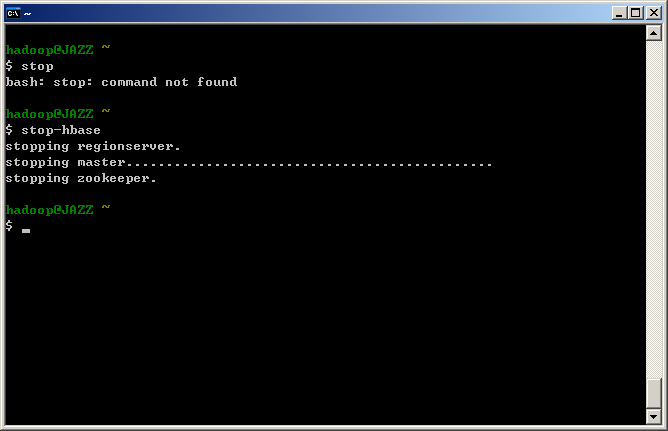
- 欲離開 Cygwin 環境前或者要暫時關閉 Hadoop 系統時,請輸入指令『stop-hadoop』。註:目前下 exit 指令登出時會執行 stop-hbase 與 stop-hadoop 的動作。
$ stop-hadoop
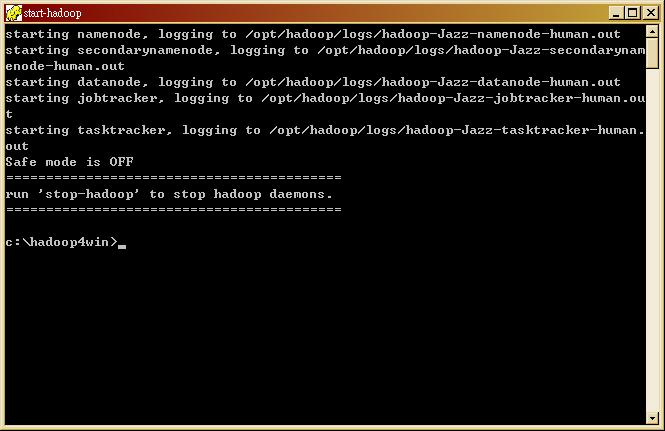
- 欲重新啟動 Hadoop 系統時,請輸入指令『start-hadoop』。
$ start-hadoop

測試 HBase 的步驟
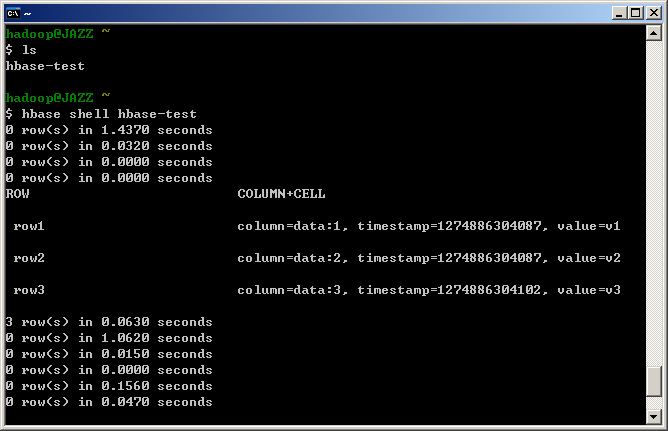
- STEP 10 : 安裝完畢後,預設已先開啟 HBase 與 Hadoop 的 Daemon,因此可以直接執行 HBase 的測試。請回到家目錄,並輸入指令『hbase shell hbase-test』。
- 註一:這個 hbase-test 存放在安裝帳號身分的家目錄中,倘若用其他帳號登入,可能會找不到。
- 註二:如果剛剛有下 stop-hadoop 的話,一定要記得 start-hadoop,因為 HBase 的資料表格是存在 HDFS 之上。
$ cd ~ $ hbase shell hbase-test

- STEP 11: 您也可以輸入指令『hbase shell』進入互動式的 HBase 指令列。您可以嘗試用底下列舉的指令,重現 hbase-test 的過程。
$ hbase shell
create 'test','data' put 'test','row1','data:1','v1' put 'test','row2','data:2','v2' put 'test','row3','data:3','v3' scan 'test' disable 'test' drop 'test' list exit

- 欲離開 Cygwin 環境前或者要暫時關閉 HBase 系統時,請輸入指令『stop-hbase』。需提醒您的是 HBase 因採用 ZooKeeper,有時關閉 master 的速度會比較慢,請耐心等候。註:目前下 exit 指令登出時會執行 stop-hbase 與 stop-hadoop 的動作。
$ stop-hbase

- 倘若是已經關閉 Cygwin 視窗,第二次重新執行 C:\hadoop4win\Cygwin.bat,請輸入指令『start-hbase』,目前 start-hbase 會視目前 java process 判斷 hadoop 是否存在而執行『start-hadoop』。
$ start-hbase

測試 WordCount 編譯
- 首先請回到家目錄,建立一個程式專案的目錄,假設取名為 my-code
~$ cd ~$ mkdir my-code ~$ cd my-code
- 接著,建立一個目錄 src 用來存放 Java 原始碼。並且下載 build.xml 到 my-code 目錄中。
~/my-code$ mkdir -p src ~/my-code$ wget http://www.classcloud.org/hadoop4win/build.xml
- 然後將您要編譯的 Java 原始碼置於 src 目錄中(開啟檔案總管,存到 c:\hadoop4win\home\${user}\my-code\src)
- 這裡我們提供一個 WordCount.java 作為示範。
~/my-code$ wget http://www.classcloud.org/hadoop4win/WordCount.java -O src/WordCount.java
- 執行 ant 指令開始編譯,結果會出現在 output.jar ,並且會產生對應的 javadoc 文件在 doc 目錄中。
~/my-code$ ant
- 用 Hadoop 執行剛剛產生的 output.jar 當作 MapReduce Job。
- 註:output.jar 因為沒有設定 manifest 所以必須指定要跑的 Main Class 名稱
~/my-code$ /opt/hadoop/bin/hadoop jar output.jar WordCount input my-output
關閉視窗
- 當您關閉 Cygwin 視窗時,建議下 exit 指令,以觸發 stop-hbase 與 stop-hadoop 指令。
- 若您直接關閉視窗,會造成 java 與 bash 執行程式遺留於背景中。此時,您可以使用 cmd.exe 並執行以下指令強制清除 java 執行程式。
taskkill /F /IM java.exe taskkill /F /IM bash.exe
電腦重開
- [備註] 若需要重新啟動 Cygwin 環境,請至 C:\hadoop4win 目錄執行 cygwin.bat 批次檔
- 當您重新開啟 Cygwin 時,並不會自動幫您執行 start-hadoop 與 start-hbase,請依您的使用需求自行啟動。
已知問題
- [備註] 由於 Hadoop 0.20.2 的 HDFS 檢查比較嚴謹,因此單機狀態下,您會看到 http://localhost:50070 顯示『Safe Mode is ON』等字樣,代表 HDFS 目前是被封鎖住寫入權限,需等待至少 30 秒以後才會恢復正常。亦因此,http://localhost:50030 若剛開始沒有 Task Tracker 連上來,也是因為 HDFS 處於安全模式(Safe Mode)造成,須等 30 秒後切回正常模式才會連上。(FIXED @ 0.1.4)
- <解決方法> 若您執行完 start-hadoop 後,看到如上圖的情形,您可以使用以下指令強制離開 Safe Mode
$ /opt/hadoop/bin/hadoop dfsadmin -safemode leave

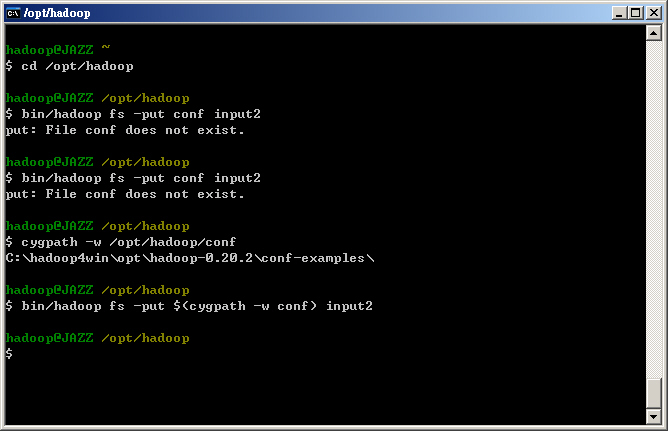
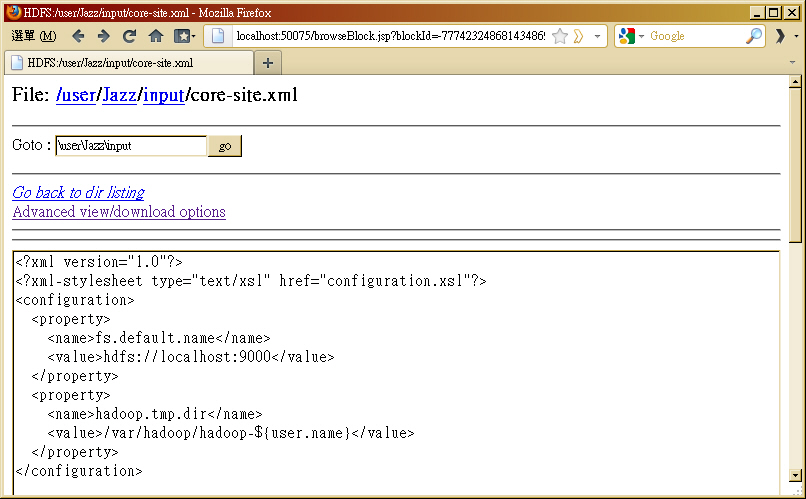
- 由於 Cygwin 的路徑並無法正常被 Hadoop 解析,亦即 Hadoop 經過 Windows OS 告知路徑為 C:\hadoop4win\opt\hadoop\ 但在 Cygwin 中卻為 \opt\hadoop。因此倘若您看到 File XXXX does not exist 的問題,可用 cygpath -w 指令把路徑轉變成 Windows 絕對路徑,就可以解決。例如:
hadoop@JAZZ ~ $ cd /opt/hadoop hadoop@JAZZ /opt/hadoop $ bin/hadoop fs -put conf input2 put: File conf does not exist. hadoop@JAZZ /opt/hadoop $ cygpath -w /opt/hadoop/conf C:\hadoop4win\opt\hadoop-0.20.2\conf-examples\ hadoop@JAZZ /opt/hadoop $ bin/hadoop fs -put $(cygpath -w conf) input2

Windows 7 常見問題
- 若您在 Windows 7 底下無法看到 jps 的結果,欲啟動 Hadoop 請執行以下指令:
taskkill /f /im java.exe /opt/hadoop/bin/hadoop-daemon.sh start namenode /opt/hadoop/bin/hadoop-daemon.sh start secondarynamenode /opt/hadoop/bin/hadoop-daemon.sh start datanode /opt/hadoop/bin/hadoop-daemon.sh start jobtracker /opt/hadoop/bin/hadoop-daemon.sh start tasktracker
- 若您在 Windows 7 底下要關閉 Hadoop 的所有服務,請使用以下指令
/opt/hadoop/bin/hadoop-daemon.sh stop tasktracker /opt/hadoop/bin/hadoop-daemon.sh stop datanode /opt/hadoop/bin/hadoop-daemon.sh stop secondarynamenode /opt/hadoop/bin/hadoop-daemon.sh stop jobtracker /opt/hadoop/bin/hadoop-daemon.sh stop namenode
Last modified 13 years ago
Last modified on May 17, 2013, 12:03:06 AM
Attachments (49)
- hadoop4win_01.jpg (278.7 KB) - added by jazz 16 years ago.
- hadoop4win_02.jpg (116.5 KB) - added by jazz 16 years ago.
- hadoop4win_03.jpg (55.6 KB) - added by jazz 16 years ago.
- hadoop4win_05.jpg (119.4 KB) - added by jazz 16 years ago.
- hadoop4win_06.jpg (180.8 KB) - added by jazz 16 years ago.
- hadoop4win_07.jpg (196.7 KB) - added by jazz 16 years ago.
- hadoop4win_08.jpg (208.6 KB) - added by jazz 16 years ago.
- hadoop4win_09.jpg (205.0 KB) - added by jazz 16 years ago.
- hadoop4win_10.jpg (234.8 KB) - added by jazz 16 years ago.
- hadoop4win_11.jpg (277.5 KB) - added by jazz 16 years ago.
- hadoop4win_12.jpg (176.9 KB) - added by jazz 16 years ago.
- hadoop4win_13.jpg (158.6 KB) - added by jazz 16 years ago.
- hadoop4win_14.jpg (161.8 KB) - added by jazz 16 years ago.
- hadoop4win_15.jpg (291.6 KB) - added by jazz 16 years ago.
- hadoop4win_16.jpg (195.2 KB) - added by jazz 16 years ago.
- hadoop4win_17.jpg (125.2 KB) - added by jazz 16 years ago.
- hadoop4win_18.jpg (247.0 KB) - added by jazz 16 years ago.
- hadoop4win_04.jpg (192.9 KB) - added by jazz 16 years ago.
- hadoop4win_19.jpg (193.4 KB) - added by jazz 16 years ago.
- hadoop4win_20.jpg (71.5 KB) - added by jazz 16 years ago.
- hadoop4win_21.jpg (84.5 KB) - added by jazz 16 years ago.
- hadoop4win_22.jpg (122.0 KB) - added by jazz 16 years ago.
- hadoop4win_23.jpg (117.9 KB) - added by jazz 16 years ago.
- hadoop4win_24.jpg (94.7 KB) - added by jazz 16 years ago.
- hadoop4win_25.jpg (124.2 KB) - added by jazz 16 years ago.
- hadoop4win_26.jpg (57.6 KB) - added by jazz 16 years ago.
- hadoop4win_27.jpg (84.3 KB) - added by jazz 16 years ago.
- hadoop4win_28.jpg (95.2 KB) - added by jazz 16 years ago.
- hadoop4win-installer_01.jpg (31.6 KB) - added by jazz 15 years ago.
- hadoop4win-installer_02.jpg (111.4 KB) - added by jazz 15 years ago.
- hadoop4win-installer_03.jpg (101.9 KB) - added by jazz 15 years ago.
- hadoop4win-installer_04.jpg (98.0 KB) - added by jazz 15 years ago.
- hadoop4win-installer_05.jpg (101.9 KB) - added by jazz 15 years ago.
- hadoop4win-installer_06.jpg (65.7 KB) - added by jazz 15 years ago.
- hadoop4win-installer_06_1.jpg (75.3 KB) - added by jazz 15 years ago.
- hadoop4win-installer_06_2.jpg (76.4 KB) - added by jazz 15 years ago.
- hadoop4win-installer_07.jpg (68.3 KB) - added by jazz 15 years ago.
- hadoop4win-installer_08.jpg (97.4 KB) - added by jazz 15 years ago.
- hadoop4win-installer_09.jpg (61.7 KB) - added by jazz 15 years ago.
- hadoop4win-installer_10.jpg (140.8 KB) - added by jazz 15 years ago.
- hadoop4win-installer_11.jpg (31.3 KB) - added by jazz 15 years ago.
- hadoop4win-uninstall_01.jpg (77.2 KB) - added by jazz 15 years ago.
- hadoop4win-uninstall_02.jpg (73.8 KB) - added by jazz 15 years ago.
- hadoop4win-uninstall_03.jpg (142.0 KB) - added by jazz 15 years ago.
- hadoop4win_29.jpg (88.5 KB) - added by jazz 15 years ago.
- hadoop4win_30.jpg (414.0 KB) - added by jazz 15 years ago.
- hadoop4win_31.jpg (172.8 KB) - added by jazz 15 years ago.
- hadoop4win_32.jpg (142.3 KB) - added by jazz 15 years ago.
- 12-04-15_hadoop4win_1.5_en.PNG (28.5 KB) - added by jazz 13 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}